❤️C语言语法笔记 一步搞定基础语法
C基本概念
C 基础语法格式
在 C 语言中,令牌(Token)是程序的基本组成单位,编译器通过对源代码进行词法分析,将代码分解成一个个的令牌。
令牌与类型
C 语言的令牌主要包括以下几种类型:
- 关键字(Keywords)
关键字是 C 语言预定义的单词, 具有特殊的含义,你不能把它们用作变量名或函数名.
数据类型: int, float, char, double, void, short, long, _Bool, _Complex, _Imaginary, enum, struct, union
控制流: if, else, switch, case, default, while, for, do, break, continue, goto, return, _Noreturn, inline
储存/修饰: static, extern, auto, register, / typedef, const, volatile, signed, unsigned,/ restrict, _Atomic, _Thread_local, _Alignas, _Alignof
存储类:控制变量存放位置、作用域、生命周期
类型修饰: 控制变量特性
- 标识符(Identifiers)
标识符是程序员定义的名字,用来表示变量、函数、数组、结构体、宏等。
- 常量(Constants)
常量是程序运行过程中 值不会改变的量。
- 字符串字面量(String Literals)
字符串字面量是用 双引号括起来的字符序列。
- 格式说明符(Format Specifier)
它们通常出现在 printf、scanf 等函数里,用来告诉编译器如何格式化输出或输入数据的类型。
| 格式说明符 | 用途 | 示例 |
|---|---|---|
%d |
输出或输入 十进制整数 | int a = 10; printf("%d", a); |
%f |
输出或输入 浮点数 | float x = 3.14; printf("%f", x); |
%c |
输出或输入 单个字符 | char ch = 'A'; printf("%c", ch); |
%s |
输出或输入 字符串 | char str[] = "Hello"; printf("%s", str); |
%x |
输出 十六进制整数 | int n = 255; printf("%x", n); |
%o |
输出 八进制整数 | int n = 8; printf("%o", n); |
%p |
输出 指针地址 | int *ptr = &a; printf("%p", ptr); |
- 运算符(Operators)
算术运算符: +-*/%
赋值运算符: =+=-=*=/=%=
比较运算符: ==!=><>=<=
逻辑运算符: &&||!
位运算符: &|^~<<>>
自增自减: ++--
- 分隔符(Separators)
; 语句结束符
{ } 块(代码块、函数体)
( ) 函数调用、表达式分组
[ ] 数组下标
, 参数分隔符、逗号运算符
# 预处理指令
" 双引号(字符串)
' 单引号(字符)
| 类型 | 示例 | 用途 |
|---|---|---|
| 标识符 | age, salary, printMessage |
用来命名变量、函数、数组、结构体等程序元素 |
| 常量 | 10, 3.14, 'a', MAX |
表示在程序运行中不会改变的值 |
| 字符串字面量 | "Hello", "C语言" |
用于表示文本数据 |
| 运算符 | `+ - * / % = == != && | 参与运算 |
| 分隔符 | ; { } ( ) [ ] , # " ' |
用于分隔语句、代码块、函数参数、数组下标、预处理指令等 |
C 程序的基本结构
预处理器指令
- 预处理器指令:如
#include和#define。
在代码正式编译之前,由“预处理器”先行处理
#include 将另一个文件的内容完整地复制并粘贴到当前位置。
用法:
#include <filename>:去系统标准路径找文件(通常是标准库)。
#include "filename": 先在当前项目目录找,找不到再去系统路径找
#define 宏定义,在程序编译前进行“查找并替换”
用法:
定义常量 #define PI 3.14159
定义宏函数 #define SQUARE(x) ((x) * (x)) 像函数一样接收参数,但本质还是代码替换。
主函数
主函数:每个 C 程序都有一个 main() 函数。
变量和数据类型
- 变量声明:声明程序中使用的变量。
基础数据类型:
| 类型 | 关键字 | 用途 | 示例 |
|---|---|---|---|
| 整型 | int |
存储整数(正、负、零)。 | int age = 25; |
| 字符型 | char |
存储单个字符或小整数(ASCII)。 | char grade = 'A'; |
| 单精度浮点型 | float |
存储小数,精度约 6-7 位有效数字。 | float price = 9.99f; |
| 双精度浮点型 | double |
存储高精度小数,精度约 15-17 位。 | double pi = 3.14159265; |
| 无值型 | void |
通常用于函数返回值或指针,表示“无类型”。 | void *ptr; |
数值类型的存储区别主要体现在内存占用(字节数)、数值范围以及底层二进制表示法
如果一个函数不接受任何参数,在 C 语言中推荐显式地写上
void。这比留空更严谨,因为它明确告诉编译器:此函数绝对不接受任何参数。配合
short,long,signed,unsigned还可以衍生出unsigned int(无符号整型)或long long(超长整型)等
复合数据类型:
数组 (Array)
用法: int numbers[5] = {1, 2, 3, 4, 5};
结构体 (Structure) - 将不同类型的数据包装成一个整体。
用法
struct Student {
char name[20];
int id;
};
struct Student s1 = {"Alice", 101};
联合体 (Union) - 所有成员共用同一块内存,一次只能存储其中一个成员。
用法: union Data { int i; float f; };
枚举 (Enumeration) - 定义一组命名的整型常量,增加代码可读性
用法: enum Color { RED, GREEN, BLUE };
指针 (Pointer) - 存储内存地址的变量
用法: int *p = &age;
- 函数定义:定义程序中使用的函数。
一个C语言程序的结构
#include <stdio.h> // 头文件包含
#define PI 3.14159 // 宏定义
// 函数声明
int add(int a, int b);
int main() { // 主函数
// 变量声明
int num1, num2, sum;
// 用户输入
printf("Enter two integers: ");
scanf("%d %d", &num1, &num2);
// 函数调用
sum = add(num1, num2);
// 输出结果
printf("Sum: %d**\n**", sum);
return 0; // 返回 0 表示程序成功执行
}
// 函数定义
int add(int a, int b) {
return a + b;
}
C语言的编译过程
编译器gcc
编译器gcc: 预处理-编译-汇编-链接-可执行文件
| 步骤 | 输入 | 输出 | 主要任务 |
|---|---|---|---|
| 预处理 | .c / .cpp |
.i (文本) |
处理 # 开头的指令,宏展开 |
| 编译 | .i |
.s (汇编) |
语法检查,生成汇编指令 |
| 汇编 | .s |
.o (二进制) |
将汇编指令转为机器码 |
| 链接 | .o + 库 |
可执行文件 | 解决符号引用,合并多个文件 |
1.预处理
纯粹的文本处理。预处理器(Preprocessor)并不理解 C++ 语法(比如它不知道什么是变量、类或函数),它只是机械地按照你的“指令”(以 # 开头的行)对源代码进行改写。
包含文件: 把 #include 指向的头文件内容直接“复制粘贴”到源文件中。
宏替换: 把所有的 #define 宏定义展开(比如把代码里的 PI 全部换成 3.14159)。
条件编译: 根据 #ifdef 等指令决定保留或删掉哪部分代码。
结果: 生成一个依然是文本格式的临时文件(通常以 .i 结尾)。
2.编译
将预处理后的代码翻译成汇编语言
词法/语法分析: 检查你的语法有没有错(比如漏了分号或括号)。
优化: 编译器会试图让你的代码运行得更快(比如删掉永远不会运行的代码)。
生成汇编: 将高级语言逻辑转换成特定 CPU 架构(如 x86 或 ARM)能理解的低级指令。
结果: 生成汇编代码文件(通常以 .s 结尾)。
3.汇编
纯粹的“翻译”,几乎没有逻辑上的改动
查表翻译: 汇编器将汇编指令(如 MOV, ADD)对应到 CPU 的机器码(二进制 0 和 1)。
结果: 生成目标文件(Object File,通常以 .o 或 .obj 结尾)。虽然这已经是二进制了,但它还不能直接运行。
3.链接
这是最后的“组装”阶段。一个项目通常包含很多个源文件和引用的库文件,链接器负责把它们粘在一起。
符号解析: 如果你在 A 文件里调用了 B 文件里的函数,链接器会找到那个函数的准确位置。
库合并: 把标准库(如 printf 的实现)合并进来。
地址分配: 确定程序在运行时代码和数据的内存布局。
结果: 生成最终的可执行文件(如 Windows 下的 .exe 或 Linux 下的 a.out)。
C语言中的指针
0.变量内存申请问题
- 核心比喻:酒店房间与门牌号
想象内存就像一家拥有无限多房间的酒店。
- 变量 (
int a = 10):这就是房间。你在房间里放了数字10。 - 内存地址 (
&a):这是房间的门牌号(例如:0x7fff)。每个房间都有唯一的门牌号。 - 指针 (
int \*p):这是一张小纸条。这张纸条上写的不是数字10,而是那个房间的门牌号(0x7fff)。
总结:指针就是一个专门用来存放“内存地址”(门牌号)的变量。
- 三大关键操作符
理解指针,其实就是理解这三个符号的配合:
| 符号 | 名称 | 作用 (用酒店比喻) | 代码示例 |
|---|---|---|---|
\* (定义时) |
声明指针 | 告诉电脑:“我要准备一张纸条(指针),专门存这种房间的门牌号”。 | int *p; |
& |
取地址符 | 查看房间的门牌号。 | p = &a; (把 a 的门牌号抄到纸条 p 上) |
\* (使用时) |
解引用 | 根据纸条上的门牌号,找到那个房间,并进去操作。 | *p = 20; (找到 p 指向的房间,把里面的东西改成 20) |
⚠️ 注意:
*号最容易让人晕。
- 在定义时 (
int *p),它只是个身份标记,表示p是个指针。- 在使用时 (
*p = ...),它是一个动作,代表“穿越”到那个地址去。
3.代码实战:瞬间看懂
看这段简短的代码,彻底理解它是如何“隔空取物”的:
C
#include <stdio.h>
int main() {
int a = 10; // 1. 有一个房间 a,里面放着 10
int *p; // 2. 准备一张纸条 p
p = &a; // 3. 把 a 的门牌号写在纸条 p 上 (此时 p 指向 a)
printf("修改前 a = %d\n", a); // 输出 10
*p = 100; // 4. 关键步!对着纸条 p 念咒语(*):
// “找到纸条上写的那个房间,把里面的值改成 100”
printf("修改后 a = %d\n", a); // 输出 100
// (虽然没直接动 a,但 a 的值变了!)
return 0;
}
发生了什么?
你没有直接操作变量 a,而是通过指针 p 找到了 a 的地址,并修改了那块内存里的数据。
- 为什么要用指针?(核心价值)
你可能会问:“直接用 a 不就好了吗?为什么要绕弯路用指针?”
主要有三个原因:
- 直接修改外部变量(函数传参)
- C语言函数默认是“复制一份数据”(传值)。如果你想在函数里修改外面的变量(例如交换两个数
swap),必须传地址(指针),函数才能顺着地址爬出来修改原来的变量。 - 高效传输大数据 - 如果你有一个几百兆的结构体(比如一张高清大图的数据),传值会发生“全量拷贝”,非常慢。传指针只需要传一个“门牌号”(通常只有 4 或 8 字节),速度极快。
- 动态内存管理 - 有些数据的大小在写代码时不知道(比如用户输入的一篇文章),需要在运行时动态申请内存。这块新申请的内存没有名字,只能通过指针(地址)来找到它。
避坑指南
- 1野指针 (Wild Pointer):定义了指针但没给它赋值。
- 比喻:纸条上写着乱码,你照着去找,可能找到别人的房间,操作会导致程序崩溃。
- 解决:定义时如果不知道指哪,先写
int *p = NULL;。 - 2类型匹配:
int类型的变量地址,只能给int *类型的指针。 - 比喻:普通的纸条记不住总统套房的门牌号规则。
C#语法学习
数据的表现形式
常量
在程序运行过程中,其值不能被改变的量称为常量
常量有以下几类:
(1)整型常量:如 1000,12345,0,-234 等
(2)实型常量:十进制小数形式、指数形式
(3)字符常量:① 普通字符,用单撇号括起来的一个字符,如 'a', 'Z' 等 ② 转义字符,如 '\'','\' 等
(4)字符串常量:用双引号引起来的多个字符,如 "China" 等
(5)符号常量:用 #define 指令,指定用一个符号名称代表一个常量,如:
#define PI 3.1416
符号常量的优点:含义清楚、一改全改
变量
变量代表一个有名字的、具有特定属性的一个存储单元,它用来存放数据,也就是存放变量的值。在程序运行期间,变量的值是可以改变的。
变量必须先定义,后使用。
常变量
C99 允许使用常变量:
const int AMOUNT = 100;
常变量是有名字的不变量,而常量是没有名字的不变量。
常变量和符号常量有什么不同?
答:定义符号常量用 #define 指令,它是预编译指令,它知识用符号常量代表一个字符串,在预编译时仅是进行字符替换,在预编译后,符号常量就不存在了,对符号常量的名字是不分配存储单元的。而常变量要占用存储单元,有变量值,只是该值不改变。
标识符:
标识符就是一个对象的名字。如变量名、函数名等等
C语言规定标识符只能由字母、数字和下划线 3 种字符组成,且第一个字符必须为字母或下划线。
数据类型
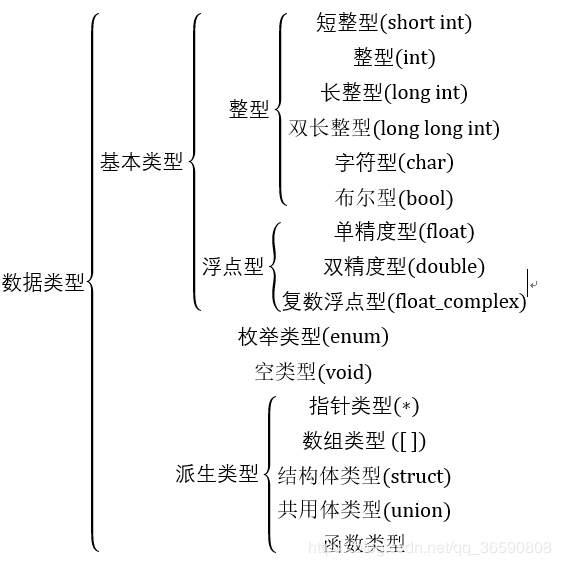
int 型
- 编译系统分配给 int 型数据 2 个字节或 4 个字节(VC++ 6.0 就是分配 4 个字节)。
-
在存储单元中的存储方式:用整数的补码形式存放。
-
int 表示一个寄存器的大小
short int 型
- 分配 2 个字节
long int 型
- 分配 4 个字节,在一个整数的末尾加大写字母 L 或小写字母 l 即可表示为 long int 型
long long int 型
- 分配 8 个字节
字符 char 类型
- 分配 1 个字节
float 类型(单精度浮点型)
- 分配 4 个字节
double 类型(双精度浮点型)
- 分配 8 个字节
long double 类型(长双精度浮点型)
- Turbo C 分配给 long double 16 个字节
- Visual C++ 6.0 分配 8 个字节
关键字和保留标识符
| auto | break | case | char | const |
|---|---|---|---|---|
| continue | default | do | double | else |
| enum | extern | float | for | goto |
| if | int | long | register | return |
| short | signed | sizeof | static | struct |
| switch | typedef | union | unsigned | void |
| volatile | while | inline | restrict |
赋值和初始化
- 变量初始化
- <类型名称><变量名称> = <初始值>;
- eg. int price = 0;
运算符和算子
算子
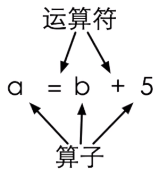
int a = b + 5;
- 计算时间差
#include "stdio.h"
/*计算时间差*/
int main()
{
int hour1, minute1;
int hour2, minute2;
scanf("%d %d", &hour1, &minute1);
scanf("%d %d", &hour2, &minute2);
int t1 = hour1 * 60 + minute1;
int t2 = hour2 * 60 + minute2;
int t = t2 - t1;
printf("时间差是 %d 小时 %d 分钟。",t/60, t%60);
return 0;
}
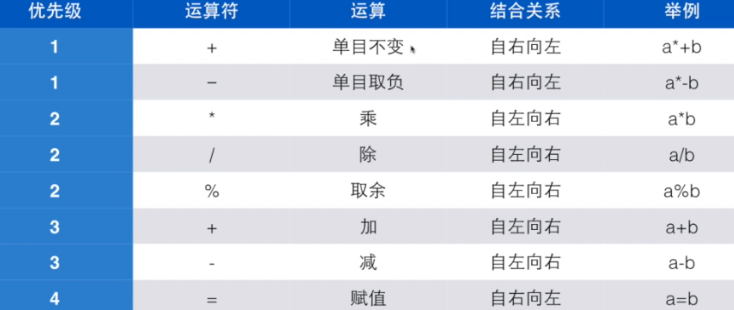
运算符优先级
自增、自减运算符
++i 、--i :使用 i 之前,先使 i 的值加(减)1
i++ 、i-- :在使用i之后,使 i 的值加(减)1
自增、自减运算符只能用于变量,而不能用于常量或表达式。
强制类型转换运算符
(类型名)(表达式)
求字节数运算符
sizeof
数据的输入输出
scanf (格式输入)、printf (格式输出)
getchar (输入字符)、putchar (输出字符)
gets (输入字符串)、puts (输出字符串)
在使用它们之前需要在开头用预处理指令 #include
| 占位符 | 数据类型 | 说明 |
|---|---|---|
%d |
int |
有符号十进制整数 |
%f |
float |
单精度浮点数 |
%lf |
double |
双精度浮点数(scanf 必须加 l) |
%c |
char |
单个字符 |
%s |
char[] |
字符串(遇空格/回车停止) |
%p |
void* |
指针地址 |
%x / %X |
int |
十六进制整数 |
printf 函数的一般格式
printf (格式控制,输出列表)
例如:printf (" %f 约等于 %d ", i , c );
1 类型安全
- 强类型
- 早期语言强调类型,面向底层的语言强调类型
- C语言需要类型,但是对类型的安全检查并不足够
2 sizeof
- 是一个静态运算符,给出某个类型或者变量在内存中所占据的字节数
- sizeof(int)
- sizeof(i)
- Example 01:
#include <stdio.h>
int main()
{
int a = 6;
printf("sizeof(int)=%ld\n",sizeof(int));
printf("sizeof(a)=%ld\n",sizeof(a));
return 0;
}
3 补码
- Example 01:
#include <stdio.h>
int main()
{
char c = 255;
int i = 255;
printf("c=%d,i=%d\n",c,i);
return 0;
}
4 unsigned
- 无符号整数型(0-255)
- 255u
- 用 l 或 L 表示 long
- unsigned 的初衷并非是扩展数能表达的范围,而是为了做纯二进制运算,主要是为了移位
整数的输入输出
- 只有两种形式:int 或 long long
- %d:int
- %u:unsigned
- %ld:long long
-
%lu:unsigned long long
-
Example 01:
#include <stdio.h>
int main()
{
char c = -1;
int i = -1;
printf("c=%u,i=%u\n",c,i);
return 0;
}
- Example 02:八进制和十六进制转换为十进制
#include <stdio.h>
int main()
{
char c = 012;//八进制
int i = 0x12;//十六进制
printf("c=%d,i=%d\n",c,i);
return 0;
}
- Example 03:八进制和十六进制输出
#include <stdio.h>
int main()
{
char c = 012;//八进制
int i = 0x12;//十六进制
printf("c=0%o,i=0x%x\n",c,i);
printf("c=0%o,i=0x%X\n",c,i);
return 0;
}
浮点数的输入输出
- float (4字节) 输入 %f 格式,输出 %f 或 %e
-
double (8字节)输入 %lf 格式,输出 %lf 或 %e
-
科学计数法:-5.67E+16
- 输出精度:
- 在 % 和 f 之间加上 .n 可以指定输出小数点后几位,这样的输出是做4舍5入的
- printf("%.3f\n",-0.0046);
#include <stdio.h>
int main()
{
printf("%.3f\n",-0.0046);
printf("%.30f\n",-0.0046);
printf("%.3f\n",-0.00046);
return 0;
}
- 超过范围的浮点数:
- printf 输出 inf 表示超过范围的浮点数:±∞
-
printf 输出 nan 表示不存在的浮点数
-
Example 01:
#include <stdio.h>
int main()
{
printf("%f\n",12.0/0.0);
printf("%f\n",-12.0/0.0);
printf("%f\n",0.0/0.0);
return 0;
}
- 浮点运算的精度
- f1 == f2 可能值相等,但不等
- 利用 fabs(f1-f2)<1e-12
字符的输入输出
-
如何输入 ‘1‘ 这个字符给 char c?
-
scanf("%c",&c);
-
```c #include
int main() { char c; scanf("%c",&c); printf("c=%d\n",c); printf("c=%c\n",c);
return 0;}
```
-
Example 01:
#include <stdio.h>
int main()
{
char c;
char d;
c = 1;
d = '1';
if(c == d){
printf("相等\n");
}else{
printf("不相等\n");
}
printf("c=%d\n",c);
printf("d=%d\n",d);
return 0;
}
- 字母大小写转换
- a+'a'-'A' 大写字母变成小写字母
- a+'A'-'a' 小写字母变成大写字母
5 逃逸字符
| 字符 | 意义 | 字符 | 意义 |
|---|---|---|---|
| \b | 回退一格 | \ " | 双引号 |
| \t | 到下一个表格位 | \ ' | 单引号 |
| \n | 换行 | \ \ | 反斜杠本身 |
| \r | 回车 |
- Example 01:
#include <stdio.h>
int main()
{
printf("123\bA\n456");
return 0;
}
6 自动类型转换
- 当运算符的两边出现不一致的类型时,会自动转换成较大的类型
- char --> short --> int --> long --> long long
- int --> float --> double
- short ----- %hd
- long ------ %ld
7 强制类型转换
-
Example 01:
-
(int)10.2
-
(short)32
-
反例1:
-
```c #include
int main() { printf("%d\n",(short)32768);
return 0;
} ```
-
结果:-32768
-
反例2:
-
```c #include
int main() { printf("%d\n",(char)32768);
return 0;
} ```
- 结果:0
注:
强制类型转换的优先级高于四则运算
选择结构和条件判断
C 语言有两种选择语句:
if 语句-两个分支
if (表达式)
语句1
else
语句2
switch 语句-多个分支
switch(表达式)
{
case 常量1 :语句1
case 常量2 :语句2
...
case 常量n :语句n
default: 语句n+1
循环结构
while 语句
while(表达式)
语句
do...while 语句
do
语句
while(表达式);
for 语句
for(表达式1;表达式2;表达式3)
语句
改变循环执行的状态
break - 提前终止
一般形式:break;
注意:break 语句还可以用来从循环体内跳出循环体,即提前结束循环,接着执行循环下面的语句。break 语句只能用于循环语句和 switch 语句之中,而不能单独使用。
continue - 提前结束本次
一般形式:continue;
注:作用为结束本次循环,即跳过循环体中下面尚未执行的语句,转到循环体结束点之前,然后进行下一次是否执行循环的判定。
布尔 bool库
-
include
- 之后就可以使用bool和true、false
#include <stdio.h>
#include <stdbool.h>
int main()
{
bool b = 6>5;
printf("%d",b);
return 0;
}
例子:
随机数
- rand()
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//主函数
int main(){
srand(time(0));
int a = rand();
printf("%d\n",a);
return 0;
}
- x%n 的结果是[0,n-1]的一个整数
printf("%d\n",a%100);
-
Example:猜数游戏
-
Example 01:
#include <stdio.h>
int main()
{
unsigned char c = 255;
int i = 255;
printf("c=%d,i=%d\n",c,i);
return 0;
}
逻辑运算
| 运算符 | 描述 | 事例 |
|---|---|---|
| ! | 逻辑非 | !a |
| && | 逻辑与 | a && b |
| || | 逻辑或 | a || b |
函数
- 函数是一块代码,接收零个或多个参数,做一件事情,并返回零个或一个值
- 函数原型,以分号结尾,即声明
函数的定义和调用
#include <stdio.h>
// 1. 函数声明 (告诉编译器:有一个叫 is_even 的函数,返回布尔逻辑值)
int is_even(int num);
int main() {
int x = 10;
// 2. 函数调用
if (is_even(x)) {
printf("%d 是偶数\n", x);
} else {
printf("%d 是奇数\n", x);
}
return 0;
}
// 3. 函数定义 (具体的逻辑实现)
int is_even(int num) {
if (num % 2 == 0) {
return 1; // 代表真
} else {
return 0; // 代表假
}
}
实例:
- Example 01:判断素数
c
int isPrime(int i){
int result = 1;
int k;
for(k=2;k<i-1;k++){
if(i%k == 0){
result = 0;
break;
}
}
return result;
}
-
Example 02:求和函数 ==> 求1到10、20到30和36到45的三个和
-
c void sum(int begin,int end){ int i; int sum = 0; for(i=begin;i<=end;i++){ sum += i; } printf("%d 到 %d 的和是 %d\n",begin,end,sum); } -
C 语言在调用函数时,永远只能传值给函数
变量范围
局部变量
- 也叫:本地变量 ==> 定义在函数内部的变量
- 生存期和作用域 ==> 大括号内,即代码块
全局变量
- 定义在函数体外面
数组
一维数组
数组大小
- const int number = 10;
- 使用 sizeof 给出整个数组所占据的内容的大小,单位是字节:
sizeof(a)/sizeof(a[0])
初始化数组
c for(i=0;i<number;i++){ count[i]=0; }
集成初始化
int a[] = {2,4,6,7,1};
-
集成初始化时的定位
int a[10] = {[0] = 2,[2] = 3,6,};
定义数组
- < 类型 > 变量名称 [ 元素数量 ]
- int number[100];
- scanf("%d",&number[i]);
- int grades[100];
- double weight[20];
-
元素数量必须是整数
-
使用数组时放在[]中的数字叫做下标或索引,下标从0开始计数
- 有效的下标范围
- [ 0 , 数组的大小 - 1 ]
数组的赋值
数组名[具体位置] = 变量名;
注:数组变量本身不能被赋值,要把一个数组的所有元素交给另一个数组,必须采用遍历
在 C 语言中,如果你定义了两个数组:
你不能直接写
b = a;。
- 底层原因:数组名
a在表达式中通常会被解释为数组首元素的地址。赋值语句b = a相当于你想修改数组b指向的内存地址。
for(i=0;i<length;i++){
b[i] = a[i];
}
数组类型转换
一维数组的转换 (Array Transformation)
int[] nums = { 1, 2, 3, 4, 5 };
// 将 int 数组转换为 string 数组
string[] strings = Array.ConvertAll(nums, x => "数字" + x);
// 或者使用 LINQ 把数字翻倍
using System.Linq;
int[] doubled = nums.Select(x => x * 2).ToArray();
数组元素的删除
一维数组的删除法 (Removal)
做法一:伪删除。把要删除的位设为 0 或 null。
做法二:真删除。创建一个长度减 1 的新数组,把剩下的搬过去。
最佳实践:如果需要频繁增删,请直接使用 List<int>。
// 删除数组中索引为 2 的元素 (数字 30)
int[] oldArr = { 10, 20, 30, 40 };
int indexToRemove = 2;
// 使用 LINQ 快速生成新数组(过滤掉索引对应的位置)
int[] newArr = oldArr.Where((val, idx) => idx != indexToRemove).ToArray();
数组运算
求总和与平均值
int sum = 0;
for (int i = 0; i < 5; i++) {
sum += scores[i]; // 累加
}
double average = (double)sum / 5; // 注意强转为浮点数,否则会丢失精度
寻找最大值/最小值
int max = scores[0];
for (int i = 1; i < 5; i++) {
if (scores[i] > max) {
max = scores[i]; // 发现更大的就更新
}
}
遍历数组输出
for(i=0;i<number;i++){
printf("%d:%d\n",i,count[i]);
}
统计数组元素数量
sizeof
int arr[] = {12, 45, 67, 89, 23, 56};
int length = sizeof(arr) / sizeof(arr[0]);
// 这样即使以后增加了数组元素,循环也不用改
求质数
static bool IsPrime(int number)
{
if (number < 2) return false;
// 只需要检查到平方根即可,效率最高
for (int i = 2; i <= Math.Sqrt(number); i++)
{
if (number % i == 0) return false; // 能整除就不是质数
}
return true;
}
// 找出 100 以内的所有质数并存入数组
int[] primes = Enumerable.Range(1, 100).Where(n => IsPrime(n)).ToArray();
一维数组的冒泡排序
冒泡排序就是通过相邻元素两两比较并交换,让最大的数像“气泡”一样逐轮交换到数列的最末端。
using System;
class Program
{
static void Main()
{
int[] arr = { 64, 34, 25, 12, 22, 11, 90 };
BubbleSort(arr);
Console.WriteLine("排序后的数组:");
// string.Join 的作用是把数组元素用逗号连接成一串文字
Console.WriteLine(string.Join(", ", arr));
}
static void BubbleSort(int[] array) // 获取数组的长度(一共有多少个数)
{
int n = array.Length;
// 外层循环:控制需要比较的轮数
for (int i = 0; i < n - 1; i++)
{
// 优化位:如果某一轮没有发生交换,说明数组已经有序
bool swapped = false;
// 内层循环:进行相邻元素的比较
// n - 1 - i 是因为每轮结束后,末尾已有 i 个元素排好序了
for (int j = 0; j < n - 1 - i; j++)
{
if (array[j] > array[j + 1])
{
// 交换元素
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
swapped = true;
}
}
// 如果本轮没发生交换,直接跳出
if (!swapped) break;
}
}
}
一维数组的选择法排序
选择法排序(Selection Sort)就是:每一轮都在剩余未排序的元素中找到那个最小的,然后把它直接交换到已排序序列的末尾。
using System;
class Program
{
// 【入口函数】:程序的起点
static void Main()
{
int[] arr = { 64, 25, 12, 22, 11 };
SelectionSort(arr);
Console.WriteLine("选择排序后的数组:");
Console.WriteLine(string.Join(", ", arr));
}
// 【核心函数】:选择排序逻辑
static void SelectionSort(int[] array)
{
int n = array.Length;
// 外层循环:负责移动“未排序部分”的起始边界
for (int i = 0; i < n - 1; i++)
{
// 1. 假设当前边界的第一个数就是最小的,记录它的下标
int minIndex = i;
// 2. 内层循环:在后面剩下的数里寻找真正的“最小值”
for (int j = i + 1; j < n; j++)
{
if (array[j] < array[minIndex])
{
// 找到了更小的,更新最小值的下标
minIndex = j;
}
}
// 3. 交换:把找到的那个真正的最小值,换到当前边界位置 i
// 每一轮外层循环只进行一次交换,效率比冒泡频繁交换要高
(array[i], array[minIndex]) = (array[minIndex], array[i]);
}
}
}
#### 二维数组(矩阵)
- int a [ 3 ] [ 5 ] 理解为 a 是一个 3 行 5 列的矩阵
内存连续性:在 C# 的内存中,二维数组是一块连续的空间。它并不是“数组的数组”,而是按行排列的线性存储(Row-major order)。
定义与初始化
类型 数组名[行数][列数] = { ... };
int a[][5] = {
{0,1,2,3,4},
{2,3,4,5,6},
}
元素引用
引用元素时,必须同时提供行索引和列索引,索引号都是从 0 开始的。
- 语法:
数组名[行下标, 列下标]
int[,] data = { { 10, 20 }, { 30, 40 } };
// 读取元素
int val = data[1, 0]; // 读取第 2 行第 1 列的元素,结果是 30
// 修改元素
data[0, 1] = 99; // 把第 1 行第 2 列的 20 改成 99
获取行数与列数
获取行数:使用 GetLength(0)
获取列数:使用 GetLength(1)
int[,] data = new int[5, 8];
int rowCount = data.GetLength(0); // 结果:5
int colCount = data.GetLength(1); // 结果:8
int totalElements = data.Length; // 结果:40 (5 * 8)
行列互换
原理:创建一个新数组,其行数等于原数组的列数,列数等于原数组的行数。然后将原数组 matrix[i, j] 的值赋给新数组的 result[j, i]
int[,] original = { { 1, 2 }, { 3, 4 }, { 5, 6 } }; // 3行2列
int rows = original.GetLength(0);
int cols = original.GetLength(1);
// 新数组的长宽与旧数组相反
int[,] transposed = new int[cols, rows];
for (int i = 0; i < rows; i++)
{
for (int j = 0; j < cols; j++)
{
// 核心:行列索引对调
transposed[j, i] = original[i, j];
}
}
遍历与求和
int sum = 0;
for (int i = 0; i < 2; i++) { // 控制行
for (int j = 0; j < 3; j++) { // 控制列
sum += matrix[i][j];
}
}
矩阵转置(行变列)
int a[3][3], b[3][3];
// 转置逻辑
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
b[j][i] = a[i][j]; // 行下标和列下标对调
}
}
求最大值及其位置
先假设第一个元素 [0, 0] 是最大值,然后遍历整个数组,一旦发现更大的,就更新最大值和它所在的坐标。
int[,] matrix = { { 1, 9, 3 }, { 4, 5, 6 } };
int maxVal = matrix[0, 0];
int maxRow = 0;
int maxCol = 0;
for (int i = 0; i < matrix.GetLength(0); i++)
{
for (int j = 0; j < matrix.GetLength(1); j++)
{
if (matrix[i, j] > maxVal)
{
maxVal = matrix[i, j];
maxRow = i; // 记录行号
maxCol = j; // 记录列号
}
}
}
Console.WriteLine($"最大值是 {maxVal},位于第 {maxRow} 行,第 {maxCol} 列");
寻找每行的最大值
for (int i = 0; i < 2; i++) {
int rowMax = matrix[i][0]; // 假设每行第一个数最大
for (int j = 1; j < 3; j++) {
if (matrix[i][j] > rowMax) {
rowMax = matrix[i][j];
}
}
printf("第 %d 行的最大值是: %d\n", i, rowMax);
}
注:列数必须给出
字符数组
字符数组 (char[]) 是存储单个字符(如字母、数字、符号)的连续序列。虽然它看起来和字符串 (string) 很像,但在底层存储和使用上有本质的区别。
存储特点:
字符数组在内存中的表现非常底层且高效:
- 连续内存分配:
字符数组在托管堆(Heap)上占据一块连续的内存空间。
- 固定长度:
一旦初始化,长度(Length)就不可改变。如果你需要增加字符,必须创建一个新数组。
- 16 位编码 (UTF-16):
在 C# 中,每个 char 类型占据 2 个字节(16位)。这意味着它原生支持 Unicode 字符(如中文、日文、特殊符号)。
- 例如:
char[] c = { 'A', '中' };在内存中实际占用 $2 \times 2 = 4$ 字节。
定义与初始化
字符数组的声明使用 char[] 关键字,字符必须用单引号 ' ' 包裹。
// --- 方式 A:先声明大小,后赋值 ---
char[] alpha = new char[3];
alpha[0] = 'A';
alpha[1] = 'B';
alpha[2] = 'C';
// --- 方式 B:声明并直接初始化 ---
char[] letters = new char[] { 'H', 'e', 'l', 'l', 'o' };
// --- 方式 C:最简写形式 ---
char[] greeting = { 'H', 'i' };
// --- 方式 D:从字符串转换而来 ---
string str = "DotNet";
char[] charArray = str.ToCharArray();
数组转换
从“数字数组”到“格式化字符串”
int[] scores = { 85, 92, 45, 60 };
// 实例:将 int[] 转换为 string[]
// 使用 Array.ConvertAll 是一种非常高效的写法
string[] descriptions = Array.ConvertAll(scores, s => s >= 60 ? $"及格({s})" : $"不及格({s})");
Console.WriteLine(string.Join(" | ", descriptions));
// 输出:及格(85) | 及格(92) | 不及格(45) | 及格(60)
高效删除
剔除数组中的偶数
因为数组长度固定,删除操作本质上是“过滤”出想要的元素并存入新数组。
using System.Linq; // 必须引入此命名空间
int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8 };
// 实例:删除所有偶数(只保留奇数)
int[] oddNumbers = numbers.Where(n => n % 2 != 0).ToArray();
Console.WriteLine(string.Join(", ", oddNumbers)); // 输出:1, 3, 5, 7
二维数组转换
求每一行的平均分
这个实例展示了如何遍历二维数组并提取有用信息。
// 每一行代表一个学生,每一列代表一门课
double[,] grades = {
{ 80, 90, 85 }, // 学生1
{ 70, 60, 65 }, // 学生2
{ 95, 98, 92 } // 学生3
};
for (int i = 0; i < grades.GetLength(0); i++)
{
double rowSum = 0;
for (int j = 0; j < grades.GetLength(1); j++)
{
rowSum += grades[i, j];
}
double avg = rowSum / grades.GetLength(1);
Console.WriteLine($"学生 {i + 1} 的平均分是: {avg:F2}");
}
反转字符串
由于 string 不可变,直接反转字符串会产生大量垃圾对象。使用 char[] 在原地反转是最专业的做法。
string original = "HelloDotNet";
// 1. 转换:string -> char[]
char[] charArray = original.ToCharArray();
// 2. 操作:首尾对调反转
int left = 0;
int right = charArray.Length - 1;
while (left < right)
{
// 使用元组交换(C# 新语法)
(charArray[left], charArray[right]) = (charArray[right], charArray[left]);
left++;
right--;
}
// 3. 转换回字符串
string reversed = new string(charArray);
Console.WriteLine(reversed); // 输出:teNtoDolleH
单词计数
在一个字符数组(或字符串)中统计单词个数,核心难点在于:如何定义“单词的开始”或“单词的结束”?
- 规则:
- 如果当前字符不是空格,且前一个字符是空格(或者是起始位置),那么我们就发现了一个新单词。
- 如果当前字符是空格,说明一个单词结束了。
char[] sentence = " Hello World from C# ".ToCharArray();
int count = 0;
bool inWord = false; // 标记位:记录当前是否正在处理一个单词
for (int i = 0; i < sentence.Length; i++)
{
if (sentence[i] != ' ') // 如果当前不是空格
{
if (!inWord) // 且之前不在单词里
{
count++; // 发现新单词,计数加1
inWord = true; // 进入单词内部状态
}
}
else // 如果遇到空格
{
inWord = false; // 退出单词状态
}
}
Console.WriteLine($"单词总数: {count}"); // 输出:4
例子 找质数存入数组
using System.Collections.Generic;
List<int> primeList = new List<int>();
for (int i = 2; i <= 50; i++)
{
bool isPrime = true;
for (int j = 2; j <= Math.Sqrt(i); j++)
{
if (i % j == 0) { isPrime = false; break; }
}
if (isPrime) primeList.Add(i);
}
// 将 List 转换为最终的一维数组
int[] primeArray = primeList.ToArray();
Console.WriteLine("1-50内的质数: " + string.Join(", ", primeArray));
指针
指针本身也是一个变量,但它不存普通数值(如整数或字符),而是专门存储另一个变量的内存地址。
为什么要用指针?
| 场景 | 作用 |
|---|---|
| 函数传参 | C语言函数默认是“值传递”。如果想在函数内部修改外部变量,必须传递指针。 |
| 动态内存分配 | 在程序运行时申请不确定大小的内存空间(如 malloc)。 |
| 数组与字符串 | 在C语言底层,数组名本质上就是一个指向首元素的指针,使用指针处理数组效率更高。 |
| 数据结构 | 构建链表、树、图等复杂结构必须依赖指针。 |
你把一个普通变量传递给函数时,C 语言并不会把变量“本体”扔进去,而是复印一份。
- 本体:你在
main函数里的原变量。- 复印件:函数参数列表里接收到的变量。
你在函数内部对参数做的任何修改,改的都是那张“复印件”,函数运行结束,复印件就被销毁了,本体毫发无伤。
#include <stdio.h>
int main() {
int a = 10; // 普通整型变量
int *p; // 声明一个指针变量 p,* 表示它是指针
p = &a; // 将变量 a 的地址赋值给 p(p 指向 a)
printf("a 的值: %d\n", a); // 输出 10
printf("a 的地址: %p\n", &a); // 输出 a 的内存地址
printf("p 的内容: %p\n", p); // 输出 p 存的内容(即 a 的地址)
printf("解引用 p: %d\n", *p); // 输出 10(通过地址找到 a 的值)
// 修改指针指向的值
*p = 20;
printf("修改后 a 的值: %d\n", a); // a 变成了 20
return 0;
}
指针与变量
| 操作类型 | 运算符/方式 | 核心目的 |
|---|---|---|
| 访问 | & (取址), * (解引用) |
读取或修改目标变量的值 |
| 传参 | func(&var) |
在函数内部改变外部变量的状态 |
| 遍历 | p++, p-- |
快速移动到下一个/上一个数据单元 |
| 动态化 | malloc, free |
实现运行时按需分配内存 |
| 控制流 | 函数指针 | 实现灵活的程序调用逻辑 |
取地址与间接访问
取地址 (&):获取一个变量在内存中的起始位置。
解引用 (\*):通过地址访问并修改该地址上存储的值。
int a = 10;
int *p = &a; // 取变量a的地址赋给指针p
*p = 20; // 间接修改a的值,此时a变为20
作为函数参数进行
函数参数默认是值传递(副本)。如果你想在函数内部修改函数外部变量的值,必须使用指针。
指针的运算
指针运算是以“步长”(即指针所指向数据类型的大小)为单位进行的,而不是简单的字节加减。
指针加减整数 (ptr + n / ptr - n)
指针自增自减
这是处理数组循环最常用的操作。
p++:指向下一个元素的起始地址。p--:指向上一个元素的起始地址。
指针减指针
ptr1 - ptr2
指针不能相加,只能相减。
- 前提条件:两个指针必须指向同一个数组。
- 结果:返回两个指针之间相隔的元素个数(类型为
ptrdiff_t),而不是字节数。 - 用途:计算数组的长度或当前位置与开头的距离。
关系运算
指针之间也可以进行大小比较。
(>, <, ==, !=)
- 相等/不等:判断两个指针是否指向同一个内存地址。
- 大小比较:判断一个元素在数组中是在另一个元素的前面还是后面。
指针与一维数组
一维数组在内存中是连续存放的,而指针就是通往这些内存地址的“导航仪”。
在绝大多数表达式中,数组名(如 arr)会被自动转换为指向数组第一个元素(arr[0])的指针。
这意味着:
- 地址相同:
arr的值 等于&arr[0]的值。 - 类型匹配:如果数组是
int类型,数组名就相当于int *类型的常量指针。
由此可以做对数组的指针运算.
既然指针存的是地址,那 p + 1 是什么意思?
- 它不是简单地让地址数字加 1。
- 它是让指针向后跳过一个元素的大小。
- 如果
p指向arr[0],那么p + 1就神奇地指向了arr[1]。
用指针访问数组元素
int arr[5] = {10, 20, 30, 40, 50};
int *p = arr; // p 指向数组开头
| 方式 | 写法 | 原理解析 |
|---|---|---|
| 下标法 | arr[i] |
也就是我们在数组中最常用的写法,直观易懂。 |
| 指针法 | *(p + i) |
1. p + i:算出第 i 个元素的地址。 2. *(解引用):取出该地址里的值。 |
指针与数组实例
#include <stdio.h>
int main() {
// 1. 定义一个包含 5 个元素的一维数组
int arr[5] = {10, 20, 30, 40, 50};
// 2. 定义一个指针,指向数组的第一个元素
// 写法 A: int *p = &arr[0];
// 写法 B (更常用): 数组名本身就是首地址
int *p = arr;
printf("--- 基础地址验证 ---\n");
printf("数组首地址 (arr): %p\n", arr);
printf("指针指向的地址 (p): %p\n", p);
printf("\n--- 访问数据的三种方式 ---\n");
// 方式一:传统的数组下标
printf("1. 使用 arr[2]: %d\n", arr[2]);
// 方式二:使用指针偏移 + 解引用
// *(p + 2) 意思是:从 p 开始向后移动 2 个位置,然后取那个值
printf("2. 使用 *(p + 2): %d\n", *(p + 2));
// 方式三:甚至可以用数组名作为指针来偏移(因为 arr 本质也是地址)
printf("3. 使用 *(arr + 2): %d\n", *(arr + 2));
printf("\n--- 使用指针遍历数组 ---\n");
// p < arr + 5 意味着指针还没指到数组末尾之后
for(int *ptr = arr; ptr < arr + 5; ptr++) {
printf("当前值: %d (地址: %p)\n", *ptr, ptr);
}
return 0;
}
指针与二维数组
二维数组指针的核心概念:
arr本质上是一个“数组的数组”。
arr是一个包含 3 个元素的数组。- 这 3 个元素里的每一个元素,又是一个包含 4 个整数的数组(一行)。
所以,arr 这个名字,代表的是第 0 行这一整行数组的首地址,而不是某一个整数的地址。
访问二维数组元素
| 也就是... | 代码写法 | 含义 |
|---|---|---|
| 找某行 | arr + i |
第 i 行的地址(单位是行) |
| 进某行 | *(arr + i) |
第 i 行 首元素 的地址(单位是 int) |
| 找某格 | *(arr + i) + j |
第 i 行 第 j 列的 地址 |
| 取某值 | *(*(arr + i) + j) |
第 i 行 第 j 列的 数值 (等价于 arr[i][j]) |
指针与二维数组实例
#include <stdio.h>
int main() {
int arr[3][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
// 定义一个指针,指向包含4个int元素的数组
// 这里的 4 必须和二维数组的列数对应
int (*p)[4] = arr;
printf("--- 地址演示 ---\n");
printf("p (第0行地址): %p\n", p);
printf("p+1 (第1行地址): %p\n", p + 1);
// 你会发现 p 和 p+1 差了 16 个字节 (4个int)
printf("\n--- 遍历数据 ---\n");
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
// 写法 A: 数组下标(最简单)
// printf("%d ", arr[i][j]);
// 写法 B: 指针运算(最硬核)
// *(*(p + i) + j)
// 翻译:(p+i)跳到第i行 -> *(...)进入第i行 -> +j 跳到第j列 -> *() 取值
printf("%2d ", *(*(p + i) + j));
}
printf("\n");
}
return 0;
}
指针数组
(处理字符串列表) 这是指针数组最经典的用法。比如我们要存三个长度不一样的名字,用二维数组很浪费空间,用指针数组最完美。
#include <stdio.h>
int main() {
// 【指针数组】
// names 是一个数组,里面存了 3 个 char* 指针
char *names[3] = {
"Apple", // 指针1 指向内存里的 "Apple"
"Banana", // 指针2 指向内存里的 "Banana"
"Cat" // 指针3 指向内存里的 "Cat"
};
for(int i = 0; i < 3; i++) {
// names[i] 拿到的是一个指针(字符串首地址)
printf("指针数组元素 %d: %s\n", i, names[i]);
}
return 0;
}
指针数组与数组指针
指针数组与数组指针的区别
| 特性 | 指针数组 int *p[4] | 数组指针 int (*p)[4] |
|---|---|---|
| 本质 | 是一个数组 | 是一个指针 |
| 大小 (32位系统) | 16字节 (4个指针 $\times$ 4字节) | 4字节 (它只是1个指针变量) |
| 结合性 | p 先结合 [] |
p 先结合 * |
| 存放内容 | 存放多个地址 | 存放一个指向整行数据的地址 |
| 步长 (p+1) | 跳到数组的下一个元素 (下一个指针) | 跳过整个数组 (跳过 4 个 int) |
| 典型应用 | 字符串数组 (char *argv[]) |
二维数组传参 |
指针与字符串数组
核心规矩:结束标志 \0
对于整型数组(int arr[]),指针不知道数组在哪里结束,所以你必须告诉它数组长度(比如 size)。
但对于字符指针,它有一个“暗号”。 C 语言规定:字符串必须以空字符 \0(ASCII 码为 0)结尾。
这对指针意味着什么? 意味着指针遍历字符串时,不再需要计数器,而是“一直走,直到撞见 \0 为止”。
使用指针遍历字符串
char *p = "Hello";
while (*p != '\0') {
// 只要没读到结尾,就一直循环
printf("%c", *p);
p++; // 指针后移
}
指针与字符串实战
#include <stdio.h>
int main() {
// 1. 定义一个普通字符数组(可修改)
char str[] = "C Language";
char *p = str; // p 指向 str 的首地址 'C'
// 2. 利用指针修改字符
*p = 'B'; // 把 'C' 变成了 'B'
*(p + 2) = '-'; // 把空格变成了 '-'
printf("修改后: %s\n", str); // 输出: B-Language
// 3. 经典的“指针遍历”写法
// 这是一个非常“C语言风味”的写法,请务必看懂
const char *text = "Hello World";
printf("逐字打印: ");
// *ptr 取出当前字符。只要它不是 0 (即不是 \0),循环就继续
// ptr++ 让指针指向下一个字符
for (const char *ptr = text; *ptr; ptr++) {
printf("[%c] ", *ptr);
}
printf("\n");
return 0;
}
const与指针
在 C 语言里,
const是一个类型修饰符(type qualifier),意思是:这个变量在“程序层面上不应该被修改”
几种类型:
| 代码声明 | const 位置 | 能改 p (地址) 吗? | 能改 *p (值) 吗? | 核心含义 |
|---|---|---|---|---|
const int *p |
* 左边 |
✅ | ❌ | 我只读数据,不改数据 |
int * const p |
* 右边 |
❌ | ✅ | 我只认这一个地址 |
const int * const p |
两边都有 | ❌ | ❌ | 完全只读 |
指向常量的指针
特征: const 在 * 的左边。
const int *p;
// 或者
int const *p;
// 这两种写法完全等价,const 都在 * 左边
- 解读: 锁住的是
\*p(内容)。 - 你可以: 改变
p的指向(让它指个新地址)。 - 你不可以: 通过
p去修改它指向的那个整数的值。 - 比喻: “游客模式”。你可以去参观不同的房间(改变地址),但你只能看,不能乱涂乱画(不能修改值)。
常量指针
特征: const 在 * 的右边。
int * const p = &a;
- 解读: 锁住的是
p(指针本身)。 - 你可以: 修改
*p的值(内容)。 - 你不可以: 改变
p的指向(也就是p必须一辈子指向初始化时的那个地址)。 - 比喻: “被焊死的门牌号”。这个门牌号(指针)已经被钉在这个房子(地址)上了,不能换到别的房子去。但是,你可以在房子里装修、换家具(修改值)。
指向常量的常量指针
特征: * 的左右两边都有 const。
const int * const p = &a;
多级指针
使用场景
概念
如果你理解了“指针就是一个存地址的变量”,那么多级指针就很好理解了:
- 普通变量 (
int a):盒子里存的是 数据(比如 100)。 - 一级指针 (
int \*p):盒子里存的是 普通变量的地址(钥匙)。 - 二级指针 (
int \**pp):盒子里存的是 一级指针的地址(存钥匙的盒子的钥匙)。
变量名: pp p a
类型: int** int* int
+------+ +------+ +------+
值: | 0xB0 | ----> | 0xC0 | ----> | 100 |
+------+ +------+ +------+
地址: 0xA0 0xB0 0xC0
语法
| 代码 | 含义 | 对应图解中的值 |
|---|---|---|
pp |
二级指针自己的值(即 p 的地址) |
0xB0 (B地点) |
*pp |
剥开第一层:取出 p 的值(即 a 的地址) |
0xC0 (C地点) |
**pp |
剥开第二层:取出 a 的值(即宝藏) |
100 |
在函数内部修改“外部指针的指向”
原理:如果你想在函数里修改一个 int 变量的值,你需要传它的地址(int*)。同理,如果你想在函数里修改一个 指针 变量的指向(比如让它指向新申请的内存),你需要传这个指针的地址(int**)。
void my_malloc(int **p) {
*p = (int*)malloc(sizeof(int)); // 修改外部指针 p 的指向
}
// 调用时:my_malloc(&ptr);
动态创建二维数组
当你不知道数组的行数和列数,需要在程序运行时用 malloc 动态申请时,通常使用二级指针。
- 结构:先申请一个指针数组(存行地址),再给每一行申请具体空间。
- 代码:
int **matrix。
处理字符串数组
场景:需要存储或传递多个字符串(比如单词列表、菜单选项)。
经典例子:main 函数的参数 char *argv[],在传递给其他函数时,这就等同于 char **argv。
链表/树结构中修改“头指针”
场景:当你在单链表中插入节点,如果操作可能会改变头节点(Head)本身(比如在空链表插入第一个节点,或者在头部插入),你需要传入头指针的地址(二级指针),否则函数里的修改出了函数就失效了。
代码:void insert_head(Node **head, int val) { ... }
函数
函数的传参
两种传参方法
| 特性 | 值传递 | 指针传递 |
|---|---|---|
| 复制内容 | 变量的具体数值 | 变量的内存地址 |
| 内存开销 | 随变量大小增加 (如结构体) | 固定大小 (通常 4 或 8 字节) |
| 安全性 | 高 (不会误伤原数据) | 较低 (需注意空指针和越界) |
| 对原变量影响 | 无影响 | 直接修改 |
值传递 (Value Transfer)
这是最基本的传递方式。系统会为形参分配新的内存空间,并将实参的值复制进去。
- 特点:函数内部对形参的修改不会影响外部实参。
- 适用场景:传递基本数据类型(int, char, float 等),且不需要在函数内改变原变量。
void swap(int x, int y) {
int temp = x;
x = y;
y = temp; // 仅交换了副本,原变量没变
}
指针传递
虽然本质上还是把“地址值”复制了一份传过去,但由于有了地址,函数可以根据地址直接操作内存。
- 特点:函数内部通过解引用(
*)操作,可以改变外部实参的值。 - 适用场景:需要在函数内修改外部变量、传递大型结构体(避免复制开销)。
void swap(int *x, int *y) {
int temp = *x;
*x = *y;
*y = temp; // 通过地址直接修改了原变量
}
数组传递
在 C 语言中,数组名在作为参数传递时,会退化 (Decay) 为指针。
- 注意点:
1. 你无法在函数内部通过
sizeof得到数组的实际长度(因为它只是个指针)。 2. 通常需要额外传递一个参数来表示数组的大小。
void printArray(int arr[], int size) {
for(int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
}
创建函数
函数声明
返回类型 函数名(参数类型1, 参数类型2, ...);
函数定义
基本语法结构
返回类型 函数名(参数类型1 参数名1, 参数类型2 参数名2, ...) {
// 函数体:要执行的代码
// 如果有返回值,使用 return 语句
}
- 返回类型 (Return Type): 函数执行完后返回给调用者的数据类型(如
int,float,char)。如果函数不返回任何值,则使用void。 - 函数名 (Function Name): 遵循标识符命名规则(通常用小写字母或下划线命名)。
- 参数列表 (Parameters): 括号内的变量用于接收外部传入的数据。如果没有参数,可以留空或写
void。 - 函数体 (Function Body): 花括号
{}内的代码块,定义了函数的功能。
函数调用
直接调用
变量名 = 函数名(实参1, 实参2, ...);
嵌套调用结构
嵌套调用就是“大任务拆解成小任务”的体现。通过这种方式,我们可以把复杂的程序拆分成许多功能单一、易于维护的小函数。
嵌套调用的逻辑:
在嵌套调用中,程序的执行顺序是:
- 执行
main函数。 main调用Function A。Function A执行到一半,调用Function B。Function B执行完毕,返回Function A。Function A继续执行完剩余代码,返回main。
递归调用结构
递归调用是嵌套调用的一种特殊形式 函数 A 调用函数 A(自己调用自己)。它本质上是嵌套调用的极限特例。
递归调用实现阶乘计算:
int factorial(int n) {
if (n <= 1) return 1; // 递归出口(没有它会造成死循环)
return n * factorial(n - 1); // 递归调用:函数内部又嵌套了自己
}
递归调用和嵌套调用的关系:
当你需要将一个大任务拆解成几个不同步奏时,使用普通嵌套(最常见)。
当你发现一个大问题可以被拆解成形式完全相同的小问题时,使用递归。
函数与数组
在 C 语言中,数组名在作为参数传递时,会“退化”为指向数组首元素的指针
函数接收数组,语法实例
// 这里的 arr[] 实际上是一个指针
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
}
int main() {
int myNumbers[] = {10, 20, 30, 40};
// 调用时,直接写数组名
printArray(myNumbers, 4);
return 0;
}
函数收到的数组是什么样子的?
当你把 myNumbers 传给函数时,函数收到的并不是那一串数字,而是一个地址(指针)。
概念:
退化为指针:数组名在作为参数传递时,会“退化”(Decay)为指向数组第一个元素的指针。也就是说,int arr[] 在编译器眼里等同于 int *arr。
共享内存:因为函数拿到了原始数组的地址,所以你在函数里修改 arr[0],main 函数里的 myNumbers[0] 也会跟着变。
失去长度感:在函数内部,sizeof(arr) 返回的是指针的大小(通常是 4 或 8 字节),而不是整个数组的大小。这就是为什么必须额外传入 size 参数的原因。
函数与一维数组
当函数接收一维数组时,通常需要两个参数:数组本身和数组的大小。
就是这个程序中的int arr[]和 int size
#include <stdio.h>
// 函数定义:计算数组平均值
// 注意:int arr[] 等价于 int *arr
float getAverage(int arr[], int size) {
int sum = 0;
for (int i = 0; i < size; i++) {
sum += arr[i];
}
return (float)sum / size;
}
int main() {
int myNumbers[] = {10, 20, 30, 40, 50};
int n = 5;
// 调用函数:直接传递数组名
float avg = getAverage(myNumbers, n);
printf("平均值是: %.2f", avg);
return 0;
}
退化现象:在函数参数列表中,int arr[] 会被编译器自动转换为 int *arr(指针)。
无法直接获取长度:在函数内部使用 sizeof(arr) 得到的是指针的大小(通常是 8 字节),而不是整个数组的大小。这就是为什么必须额外传递 size 参数的原因。
修改原数组:因为传递的是地址,函数内部对 arr[i] 的修改会直接影响到 main 函数中的原数组。
函数与二维数组
向函数传递二维数组时,必须指定第二维(列)的大小。
标准传递方式:
编译器需要知道列数,才能通过公式 地址 = 首地址 + (行索引 * 列数 + 列索引) * 类型大小 找到元素。
#include <stdio.h>
// 必须指明列数(此处为 3)
void printArray(int arr[][3], int rows) {
for (int i = 0; i < rows; i++) {
for (int j = 0; j < 3; j++) {
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
int main() {
int myTable[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
printArray(myTable, 2);
return 0;
}
为什么不能省略列数?
如果你写
void func(int arr[][]),编译器会报错。因为它不知道每一行有多长,当你访问arr[1][0]时,编译器无法计算该跳过多少个元素到达第二行。
函数与字符数组
字符串数组的核心规则:处理字符串的函数不需要传递数组长度,因为函数可以通过循环判断是否到达
\0来停止处理。
向函数传递字符数组
自定义字符串长度函数 - 注意这里不需要像整型数组那样传入 size 参数。
#include <stdio.h>
// 接收字符指针(或 char s[])
int getStrLength(char s[]) {
int count = 0;
while (s[count] != '\0') { // 只要没遇到结束符就继续
count++;
}
return count;
}
int main() {
char myName[] = "Gemini";
printf("字符串长度为: %d\n", getStrLength(myName));
return 0;
}
形参的写法
在函数头中,以下两种写法完全等价:
void func(char str[])
void func(char *str) (更符合 C 程序员的习惯)
函数与指针
指针和函数的关系包括指针作为函数参数(传址调用)和指向函数的指针(函数指针)。
指针作为函数参数(传址调用)
在 C 语言中,普通变量作为参数传递时是“值传递”,函数会创建一个副本,修改副本不会影响原变量。而使用指针,可以直接修改外部变量的值。
例如:
#include <stdio.h>
// 接收地址,通过解引用 (*) 修改原值
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int main() {
int x = 10, y = 20;
swap(&x, &y); // 传入变量的地址
printf("x = %d, y = %d\n", x, y); // 输出 x = 20, y = 10
return 0;
}
为什么要用指针传参?
- 修改实参:如上例所示,突破函数作用域限制。
- 提高效率:传递大型结构体或数组时,只需传递一个指针(4或8字节),避免拷贝大量数据。
- 实现多返回值:C 语言函数只能返回一个值,但可以通过指针参数“带回”多个处理结果。
指针作为函数返回值
函数也可以返回一个指针,但必须注意:严禁返回局部变量的地址。
int* getData() {
static int val = 100; // 必须是静态变量或全局变量,否则函数结束内存即释放
return &val;
}
函数指针 (Function Pointers)
函数在内存中也有地址,函数名本身就是该函数的首地址。我们可以定义一个指针指向这个函数,从而通过指针来调用它。
语法结构
返回值类型 (*指针变量名)(参数列表);
代码示例:回调机制的雏形:
#include <stdio.h>
int add(int a, int b) { return a + b; }
int mul(int a, int b) { return a * b; }
// 这里的 func 就是一个函数指针,作为参数传入
void calculator(int x, int y, int (*operation)(int, int)) {
printf("结果: %d\n", operation(x, y));
}
int main() {
// 灵活切换算法
calculator(5, 3, add);
calculator(5, 3, mul);
return 0;
}
构造类型
构造类型(Constructed Types)又称为“复合类型”。它是程序员根据实际需要,按照一定的语法规则,由一种或多种基本类型(如 int, char, float)有机地组合在一起形成的新数据类型。
| 构造类型 | 元素/成员类型 | 内存分布 | 主要用途 |
|---|---|---|---|
| 数组 | 必须相同 | 连续排列 | 批量处理同类数据 |
| 结构体 | 可以不同 | 各成员独立存在 | 描述复杂实体的属性 |
| 共用体 | 可以不同 | 成员覆盖(重叠) | 节省空间或多重定义内存 |
| 枚举 | 整型符号 | 存储为整数 | 增强程序逻辑的可读性 |
数组类型 (Array)
数组是将相同类型的数据按一定顺序排列的集合。
- 特点:元素类型一致,内存地址连续。
- 示例:
int scores[10];(存 10 个整数)。
结构体类型 (Structure)
结构体是将不同类型的数据组合在一起的集合。它是最常用的构造类型,用于描述复杂对象
特点:成员可以是不同的数据类型,每个成员有自己的内存空间。
有点类似于Python的面向对象, 但没有方法,只有数据
关键字:struct
示例:
struct Student {
char name[20];
int age;
float score;
};
结构体的定义与描述
你可以把结构体想象成一个“信息卡片”或“模板”。例如,要描述一个“学生”,单靠一个变量是不够的,你需要姓名(字符串)、年龄(整型)和成绩(浮点型)。
| 特性 | 说明 |
|---|---|
| 逻辑分组 | 将相关的变量组织在一起,提高代码的可读性和维护性。 |
| 内存布局 | 结构体成员在内存中通常是连续存储的(但要注意字节对齐)。 |
| 嵌套深度 | 理论上可以无限嵌套,但为了代码清晰,建议不要超过 3 层。 |
| 初始化 | 可以使用大括号 {} 进行嵌套初始化,例如:{ "李四", 21, {2004, 10, 1} }。 |
基本语法:
A. 先定义类型,再定义变量
struct Book {
char title[50];
float price;
};
struct Book b1; // 定义了一个名为 b1 的 Book 类型变量
这种方式逻辑清晰,方便在代码各处重复使用该类型。
B. 在定义类型的同时定义变量
struct Book {
char title[50];
float price;
};
struct Book b1; // 定义了一个名为 b1 的 Book 类型变量
适用于该结构体变量较少,且不需要在其他地方频繁声明的情况。
结构体成员的引用
引用成员的方式取决于你手里拿到的是变量本身还是指向变量的指针。
方式一:使用点运算符 (.)
当你直接操作结构体变量时,使用 . 访问成员。
语法: 结构体变量名.成员名
struct Book b1 = {"C语言基础", 45.5};
printf("书名: %s\n", b1.title); // 引用 title 成员
b1.price = 49.9; // 修改 price 成员
方式二:使用指向运算符 (->)
当你拥有一个指向结构体的指针时,使用 ->(也叫“箭头运算符”)访问成员。
语法: 结构体指针变量名->成员名
struct Book *ptr = &b1;
printf("价格: %.1f\n", ptr->price); // 等同于 (*ptr).price
成员引用的注意事项
- 优先级问题:点运算符
.和箭头运算符->的优先级在 C 语言中是最高的,因此在复杂的表达式中(如&ptr->price),它们会先被结合。- 嵌套引用:如果结构体里还有结构体,就一层一层“点”进去。 - 例如:
student.birthday.year- 整体赋值:同类型的结构体变量可以整体相互赋值(例如
b2 = b1;),这会拷贝所有成员的值。但注意:如果成员里有指针,这种简单的赋值可能会导致“浅拷贝”问题。
结构体的嵌套
嵌套结构体是指在一个结构体的成员中,包含了另一个已经定义的结构体。这在处理具有层次关系的数据时非常有用(例如:一个人有出生日期,而“日期”本身就是一个包含年、月、日的整体)。
嵌套示例:学生与出生日期
// 定义日期结构体
struct Date {
int year;
int month;
int day;
};
// 定义学生结构体,其中嵌套了 Date
struct Student {
char name[50];
int age;
struct Date birthday; // 嵌套在此处
};
访问嵌套成员:
访问嵌套结构体的成员需要使用两次点操作符(.)
struct Student s1;
// 初始化嵌套成员
s1.birthday.year = 2005;
s1.birthday.month = 5;
s1.birthday.day = 20;
printf("学生姓名:%s,出生年份:%d", s1.name, s1.birthday.year);
结构体内存问题及函数传参
结构体内存对齐
你可能会认为结构体的大小等于所有成员大小之和,但事实并非如此。为了提高 CPU 访问内存的效率,编译器会自动在成员之间填充一些“无用”的字节。
对齐规则:
- 起始地址:结构体变量的首地址必须是其最宽基本类型成员大小的整数倍。
- 成员偏移:每个成员相对于起始地址的偏移量,必须是该成员大小(或其内部最宽成员大小)的整数倍。
- 总大小:结构体的总大小必须是其最宽基本类型成员大小的整数倍。
例子:
struct A {
char a; // 1字节
int b; // 4字节
char c; // 1字节
}; // 结果是 12 字节 (1+空3 + 4 + 1+空3)
struct B {
int b; // 4字节
char a; // 1字节
char c; // 1字节
}; // 结果是 8 字节 (4 + 1 + 1 + 空2)
结构体作为函数参数
- 将结构体传递给函数有两种主要方式,它们的性能表现截然不同:
###### A. 值传递 (Pass by Value)
将结构体的所有内容复制一份交给函数。
- 优点:函数内部修改不会影响原变量,安全性高。
- 缺点:如果结构体很大(比如 1KB),复制操作会消耗大量时间和内存。
C
void printStudent(struct Student s) { // 发生完整拷贝
printf("%s", s.name);
}
###### B. 指针传递 (Pass by Pointer) —— 推荐做法
只传递结构体的内存地址(通常只需 4 或 8 字节)。
- 优点:效率极高,无论结构体多大,传递开销都极小。
- 缺点:函数内部可以直接修改原变量。
C
// 使用 const 关键字可以防止函数意外修改原数据
void printStudent(const struct Student *s) {
printf("%s", s->name); // 使用 -> 访问
}
共用体类型 (Union)
共用体(也叫联合体)允许在同一个内存位置存储不同的数据类型。
- 特点:所有成员共享同一块内存。在任意时刻,只有一个成员是有效的。共用体的大小等于其最大成员的大小。
- 关键字:
union - 场景:用于节省内存,或者需要对同一段数据进行不同解释时。
共用体(Union) 是一种特殊的数据类型,它允许你在同一个内存地址存储不同的数据类型。
简单来说,共用体就像是一个“多功能插座”,虽然它有很多种插口(成员),但在任何给定的时间,你只能使用其中的一个。
共用体的定义与变量声明
共用体的语法与结构体(struct)非常相似,但其本质逻辑完全不同。
定义语法:
union Data {
int i;
float f;
char str[20];
};
声明变量:
1.先定义后声明:union Data data;
2.定义时同时声明:
union Data {
int i;
float f;
} data;
共用体的嵌套定义
共用体嵌套结构体
这种方式常用于定义一个数据的不同表现形式。例如,一个 32 位的颜色值,既可以整体读取,也可以按 R、G、B、A 分量读取。
typedef union {
uint32_t full_value; // 整体作为一个 32 位整数
struct { // 嵌套一个匿名结构体
uint8_t r;
uint8_t g;
uint8_t b;
uint8_t a;
} rgba;
} Color;
// 使用示例:
Color myColor;
myColor.full_value = 0xFF00AA55;
// 此时 myColor.rgba.r 就会自动获得对应字节的值(注意大小端序影响)
结构体嵌套共用体
用于定义“变体类型”。例如,一个指令包,根据类型不同,后面的数据含义也不同。
struct Message {
int msgType;
union { // 嵌套匿名共用体
int intData;
float floatData;
char strData[4];
} payload;
};
共用体的位域
位域允许你按“位”来指定结构体成员占用的空间,这在硬件驱动开发中极其常见。
struct {
uint8_t low_four_bits : 4; // 占用 4 bit
uint8_t high_four_bits : 4; // 占用 4 bit
} byte_split;
位域的关键规则:
- 类型限制:通常使用
unsigned int或int(在 C99 后支持uint8_t等)。建议始终使用unsigned以避免符号位带来的困扰。 - 不能取地址:位域成员可能不从字节边界开始,因此不能对位域成员使用
&取地址符。 - 对齐与填充:如果相邻位域的总位数超过了基础类型的长度,编译器会将其放入下一个存储单元。
位域的操作
基础成员操作 (语法糖)
1.赋值 (Set value):
直接像给普通变量赋值一样。编译器会限制值的大小,如果超过了位域定义的宽度,会发生截断。
ctrl.bits.mode = 0x05; // 假设 mode 为 3 bit,自动处理低 3 位
2.读取 (Read value):
直接读取成员
if (ctrl.bits.enable == 1) { ... }
传统位掩码操作
| 操作 | 公式 / 示例 | 说明 |
|---|---|---|
| 置位 (Set) | reg | = MASK; |
|
| 清零 (Clear) | reg &= ~MASK; |
将特定位置 0,其余不变。 |
| 取反 (Toggle) | reg ^= MASK; |
翻转特定位(0 变 1,1 变 0)。 |
| 检测 (Test) | if (reg & MASK) |
判断某一位或几位是否为 1。 |
| 写入多位 | reg = (reg & ~MASK) | (val << SHIFT); |
先清空目标区域,再写入新值。 |
共用体与位域的结合应用
同时实现按位控制和整体赋值。
示例:控制一个 8 位寄存器
假设有一个硬件寄存器,其格式如下:
- Bit 0-2: 模式选择 (Mode)
- Bit 3: 使能位 (Enable)
- Bit 4-7: 优先级 (Priority)
typedef union {
uint8_t byte; // 用于整体操作(如 byte = 0x00 清零)
struct { // 用于精确位操作
uint8_t mode : 3; // 占 3 位
uint8_t enable : 1; // 占 1 位
uint8_t priority : 4; // 占 4 位
} bits;
} Register;
// 使用方法:
Register ctrlReg;
ctrlReg.byte = 0; // 全清零
ctrlReg.bits.enable = 1; // 开启使能,不影响其他位
ctrlReg.bits.priority = 0xA; // 设置优先级
内存占用规则
这是共用体与结构体最大的区别:共用体的大小等于其最大成员的大小,并且需要满足内存对齐的要求。
内存特点:
- 共享地址:所有成员都从同一个内存地址开始存储。
- 相互覆盖:给其中一个成员赋值,会覆盖掉其他成员的值。
- 大小计算: 1. 共用体的最小长度必须能够容纳最大的成员。 2. 最终大小必须是所有成员类型中“最大基本类型大小”的整数倍(对齐原则)。
例如:
union Sample {
char a; // 1 字节
int b; // 4 字节
double c; // 8 字节
};
最大成员是 double c,占用 8 字节。
因此,sizeof(union Sample) 的结果是 8 字节。
如果你修改了 b 的值,a 和 c 的值也会随之改变,因为它们在内存里是重叠的。
枚举类型 (Enumeration)
枚举(Enumeration,简称 Enum) 是一种特殊的数据类型,用于定义一组命名的整型常量。它能让代码更具可读性和可维护性,避免在程序中充斥大量的“魔术数字”(Magic Numbers)。
“魔术数字”(Magic Number) 指的是代码中直接出现的、没有解释说明的具体数值
枚举用于定义一组命名的整型常量,增加代码的可读性。
特点:本质上是整型(int),但通过有意义的名字代替数字。
关键字:enum
示例:
enum Week { Mon, Tue, Wed, Thu, Fri, Sat, Sun };
// Mon 默认为 0, Tue 为 1, 依此类推
等价于
#define Mon 0
#define Tue 1
#define Wed 2
#define Thu 3
#define Fri 4
#define Sat 5
#define Sun 6
枚举的定义
使用关键字 enum 来定义枚举类型。
enum 枚举名 {
标识符1,
标识符2,
...
标识符n
};
默认值与显式赋值
默认情况下: 第一个标识符的值为 0,后续标识符依次递增 1。
显式赋值: 你可以为其中的成员手动指定值。如果某个成员被赋值,它后面的成员会在此基础上继续递增。
enum Weekday {
MON = 1, // 从 1 开始
TUE, // 2
WED, // 3
THU = 10, // 跳跃到 10
FRI, // 11
SAT, // 12
SUN // 13
};
枚举变量的声明与初始化
定义好枚举类型后,可以通过以下几种方式使用:
方式一:先定义类型,再声明变量
enum Color { RED, GREEN, BLUE };
enum Color favorite_color;
favorite_color = GREEN;
方式二:使用 typedef 简化
在 C 语言中,通常使用 typedef 来省去每次都要写 enum 关键字的麻烦。
typedef enum {
STOP,
PAUSE,
PLAY
} State;
State currentState = PLAY;
枚举的实际应用
枚举最常用于 switch 语句中,使逻辑判断非常直观。
#include <stdio.h>
typedef enum {
SUCCESS = 0,
ERROR_NOT_FOUND = 404,
ERROR_SERVER = 500
} ResponseStatus;
void handleResponse(ResponseStatus status) {
switch (status) {
case SUCCESS:
printf("请求成功!\n");
break;
case ERROR_NOT_FOUND:
printf("错误:未找到资源。\n");
break;
case ERROR_SERVER:
printf("错误:服务器内部故障。\n");
break;
default:
printf("未知状态。\n");
}
}
动态内存分配
| 特性 | malloc | realloc |
|---|---|---|
| 主要功能 | 分配新内存 | 调整已分配内存的大小 |
| 对原数据影响 | 不适用(新建) | 保留原数据(扩容或截断) |
| 内存初始化 | 随机值(不初始化) | 新扩大的部分不初始化 |
| 常用场景 | 初始化数组、结构体 | 实现动态数组(Vector) |
malloc - 基础申请
malloc (memory allocation) 用于在堆上申请一块连续的内存空间。
基本使用方法
void* malloc(size_t size);
参数:size 是字节数。通常结合 sizeof 运算符使用。
返回值:成功时返回指向该空间的 void* 指针;失败时返回 NULL。
代码示例:
int *ptr = (int*)malloc(5 * sizeof(int)); // 申请能存放5个int的空间
if (ptr == NULL) {
// 内存申请失败的处理(如内存不足)
exit(1);
}
realloc - 动态扩容/缩减
realloc (re-allocation) 用于修改之前已经分配好的内存块大小。
语法与参数
void* realloc(void* ptr, size_t size);
参数:ptr 是原内存块指针,size 是新设定的总大小。
工作机制:
- 原地扩容:如果原地址后续空间充足,直接扩大并返回原指针。
- 异地扩容:如果原地址后续空间不足,它会寻找新空间、拷贝数据、释放旧内存,最后返回新地址。
free() 函数 - 动态内存分配工具
free() 的基本语法:
#include <stdlib.h>
void free(void *ptr);
参数:ptr:指向要释放的内存块的指针。该指针必须是由 malloc 系列函数返回的地址。
返回值:无。
内存分配逻辑使用
动态内存分配的生命周期通常遵循以下三个步骤:
- 分配:使用
malloc获取内存。 - 使用:检查指针是否为
NULL,然后进行读写操作。 - 释放:使用
free归还内存,并将指针置为NULL。
语法:
#include <stdio.h>
#include <stdlib.h>
int main() {
// 1. 分配空间
int *arr = (int *)malloc(5 * sizeof(int));
if (arr == NULL) {
return 1; // 分配失败处理
}
// 2. 使用空间
for (int i = 0; i < 5; i++) {
arr[i] = i * 10;
}
// 3. 释放空间
free(arr);
// 4. 重要:将指针置为空,防止“野指针”
arr = NULL;
return 0;
}
别名
typedef
typedef 关键字 为现有的数据类型创建一个别名(Alias),让代码更具可读性或更易于维护。
| 特性 | typedef | #define |
|---|---|---|
| 处理阶段 | 编译阶段 | 预处理阶段 |
| 作用范围 | 受作用域限制(如局部定义) | 全局替换(除非 #undef) |
| 安全性 | 类型安全检查 | 无类型检查,易出 Bug |
typedef的使用
typedef 原类型名 新别名;
typedef unsigned int uint; // 为无符号整型定义别名 uint
uint age = 25; // 等同于 unsigned int age = 25;
typedef的使用场景
简化结构体 (Struct)
这是 typedef 最常用的地方。如果不使用它,每次定义结构体变量都要带上 struct 关键字。
// 不使用 typedef
struct Point {
int x;
int y;
};
struct Point p1;
// 使用 typedef
typedef struct {
int x;
int y;
} Point;
Point p2; // 直接使用 Point 即可,简洁很多
定义数组类型
你可以定义一个特定长度的数组类型。
typedef int IntArray[10];
IntArray scores; // scores 是一个包含 10 个整数的数组
定义指针类型
typedef char* String;
String name = "Gemini"; // name 是一个字符指针
定义函数指针
函数指针的语法通常比较晦涩,用 typedef 可以大幅简化。
// 定义一个返回值为 int,参数为两个 int 的函数指针类型
typedef int (*CalcFunc)(int, int);
int add(int a, int b) { return a + b; }
CalcFunc myFunc = add;
int result = myFunc(5, 3);
MAKEFILE
Makefile 是在 C / C++ 项目中用来“自动化编译”的脚本文件,配合 make 命令使用,用来描述:怎么把源代码一步步编译、链接成最终程序,以及它们之间的依赖关系
Makefile = 告诉 make:哪些文件变了,就重新编哪些,不变的就不动,这在项目文件一多时非常重要。
核心语法规则
Makefile 的核心由一条或多条“规则”组成,其基本格式如下:
目标 (target): 依赖 (prerequisites)
<Tab键> 命令 (command)
目标 (Target):通常是要生成的文件名(如可执行文件或目标文件),也可以是一个动作(如 clean)。
依赖 (Prerequisites):生成目标所需要的文件。
命令 (Command):生成目标要执行的动作。注意:命令前必须是一个 Tab 字符,不能是空格。
工作原理
变量与自动变量
为了让 Makefile 更具通用性,我们通常会使用变量来管理编译器和参数。
| 变量名 | 含义 |
|---|---|
CC |
C 语言编译器,默认通常是 cc |
CXX |
C++ 编译器,默认通常是 g++ |
CFLAGS |
C 编译器的编译选项(如 -Wall -g) |
LDFLAGS |
链接器选项 |
自动变量
$@:表示当前的目标文件。$^:表示所有的依赖文件。$<:表示第一个依赖文件。
实战模板
假设你有一个项目,包含 main.c 和 tool.c,你可以这样写 Makefile:
# 1. 定义变量
CC = gcc
CFLAGS = -Wall -g
TARGET = my_program
OBJS = main.o tool.o
# 2. 终极目标:链接所有 .o 文件生成可执行程序
$(TARGET): $(OBJS)
$(CC) $(OBJS) -o $(TARGET)
# 3. 模式规则:将 .c 编译成 .o
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
# 4. 清理规则
.PHONY: clean
clean:
rm -f $(OBJS) $(TARGET)
数据结构
什么是数据结构 (Data Structure)?
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。在C语言中,我们通常从三个层面来理解它:
- 逻辑结构:数据元素之间的逻辑关系(如:一对一、一对多、多对多)。
- 物理(存储)结构:数据在计算机内存中的实际存放方式(如:顺序存储、链式存储)。
- 算法操作:对这些数据执行的操作(如:插入、删除、查找、排序)。
线性表
线性表是具有相同特性的数据元素的一个有限序列。
元素在逻辑上是一对一的线性关系,除了第一个和最后一个元素外,每个元素都有唯一的前驱和后继。
线性表具有以下几个关键特点:
- 有序性 - 元素有固定顺序(第 1 个、第 2 个……)
- 有限性 - 元素个数是有限的
- 同一类型 - 所有元素通常属于同一数据类型
- 一对一关系 - 每个元素最多只有一个前驱和一个后继
示意:
a1 → a2 → a3 → a4 → ... → an
线性表的逻辑结构:
L = (a1, a2, a3, ..., an)
a1:第一个元素(无前驱)
an:最后一个元素(无后继)
ai(2 ≤ i ≤ n-1):有且只有一个前驱和一个后继
顺序存储结构(顺序表)实现线性表
略
链式存储结构(链表)实现线性表
列
文件IO
| 功能 | 标准 I/O (C 库) | 系统 I/O (内核) |
|---|---|---|
| 打开 | fopen() |
open() |
| 关闭 | fclose() |
close() |
| 读取 | fread(), fgets() |
read() |
| 写入 | fwrite(), fprintf() |
write() |
| 定位 | fseek() |
lseek() |
| 标识 | FILE * (文件指针) |
int fd (文件描述符) |
Linux 的做法是: 把这些差异全部封装在内核的驱动程序里。驱动程序负责把硬件的电平信号、协议转换成“流”。 对于 C 程序员来说,只需要学习一套
open/read/write/close,就能控制几乎所有的硬件。
标准IO
标准 I/O(Standard Input/Output) 是指标准输入输出库(stdio.h)提供的一套用于处理数据输入和输出的函数和宏。简单来说,它是程序与外部世界(键盘、屏幕、文件)进行数据交换的“翻译官”和“中转站”。
核心概念:流(Stream)
在标准 I/O 中,所有的数据都被抽象为流。流就像一串连续的数据字节,程序不需要关心这些数据是来自键盘、硬盘还是网络。
标准 I/O 默认会自动打开三个流:
- stdin(标准输入): 默认指向键盘。
- stdout(标准输出): 默认指向屏幕。
- stderr(标准错误): 默认指向屏幕,用于输出错误信息。
与系统调用(如 Linux 中的 read, write)不同,标准 I/O 具有以下两个关键特征:
为什么叫“标准” I/O?
缓冲机制(Buffering)
这是标准 I/O 最重要的特性。它不会每读写一个字符就操作一次磁盘,而是先将数据存在内存中的缓冲区。
- 全缓冲: 缓冲区填满才写入(通常用于文件)。
- 行缓冲: 遇到换行符
\n就写入(通常用于屏幕输出printf)。 - 无缓冲: 立即写入(通常用于
stderr)。
可移植性(Portability)
标准 I/O 是 C 标准库(ANSI C)的一部分。这意味着你在 Windows 上写的 printf 代码,拿到 Linux 或 macOS 上编译,运行效果是一样的。
| 特性 | 标准 I/O (stdio.h) | 低级 I/O (系统调用) |
|---|---|---|
| 缓冲 | 自动提供缓冲区(效率高) | 无缓冲(需手动管理) |
| 可移植性 | 跨平台一致 | 依赖特定操作系统 |
| 接口 | 使用 FILE * 指针 |
使用文件描述符 (int) |
| 特性 | 标准 I/O (fopen/printf) | 系统 I/O (open/write) |
|---|---|---|
| 缓冲区 | 有(用户态缓冲) | 无(直接进内核) |
| 实时性 | 较差,有延迟 | 极高,即时生效 |
| 数据单位 | 字符、字符串、格式化数据 | 原始字节流 (void *) |
| 易用性 | 简单,像写作文 | 略复杂,需自己管理字节长度 |
| 典型场景 | 读写配置文件、打印日志、调试信息 | 驱动交互、串口通信、操作硬件节点 |
嵌入式开发中的标准IO
1. 打印调试:printf / fprintf
在嵌入式开发中,没有花哨的 GUI 界面,串口终端(Terminal) 就是你的唯一窗口。
- printf:最常用的调试手段。它将信息输出到
stdout,通常通过串口推送到你的电脑屏幕。 - fprintf(stderr, ...):非常重要! 错误信息建议输出到
stderr。因为stdout有缓冲区,程序崩溃时日志可能还没打出来就没了;而stderr通常是无缓冲的,即写即出,能帮你抓到“临终遗言”。
2. 读写配置文件:fgets / fprintf
嵌入式设备通常需要读取配置(如 IP 地址、传感器阈值)。
- 场景:读取
/etc/config.conf这种文本文件。 - 常用函数:
fopen:打开文件。fgets:小白必用。相比gets(已废弃)或scanf,fgets可以指定读取长度,防止内存溢出(嵌入式设备内存很珍贵)。fprintf:将修改后的参数写回文件。
3. 操作硬件节点:fopen / fwrite / fread
在 Linux 中,“一切皆文件”。很多硬件驱动都被抽象成了文件节点(位于 /dev/ 或 /sys/ 下)。
- 控制 GPIO(点灯/控制继电器): 你不需要写复杂的底层代码,只需要用标准 I/O 操作文件:
C
FILE *fp = fopen("/sys/class/gpio/gpio18/value", "w");
fprintf(fp, "1"); // 点亮 LED
fclose(fp);
- 读取传感器数据: 比如读取 CPU 温度:
fopen("/sys/class/thermal/thermal_zone0/temp", "r");
在 Linux 嵌入式开发中,这被称为 Sysfs 接口。Linux 内核把硬件功能映射成了磁盘上的普通文件。你不需要写复杂的底层驱动指令,只需要像“读写文档”一样操作这些文件,就能控制硬件。
在 Linux 嵌入式系统中,这不是一个普通的保存在硬盘上的文本文件,而是一个虚拟文件。
它直接对应着 CPU 内部的一个硬件寄存器。
4. 数据采集与存储:fread / fwrite
如果你在做视频监控、音频录制或传感器数据记录,需要处理二进制数据。
- 场景:把摄像头抓取的图片存成
.jpg,或者记录传感器原始采样点。 - 特点:这时不能用
fprintf(它会把数字转成字符),必须用fwrite直接把内存里的二进制字节流“搬”到磁盘上。
5. 进阶:管道通信 popen
在嵌入式 Linux 中,你经常需要调用系统命令并获取结果。
-
场景:你想在 C 程序里获取当前系统的磁盘剩余空间(
df -h)。 -
用法:
FILE *pp = popen("df -h", "r"); // 执行命令并打开一个流
fgets(buffer, sizeof(buffer), pp); // 读取命令的输出结果
pclose(pp);
系统调用IO
核心概念:文件描述符 (File Descriptor, fd)
在系统 I/O 中,没有 FILE * 指针,取而代之的是一个简单的整数,叫作 fd。
0:标准输入 (stdin)1:标准输出 (stdout)2:标准错误 (stderr)- 当你打开一个 GPIO 文件或普通文件时,系统会给你分配一个更大的整数(如
3,4...)。
依赖
#include <stdio.h>
#include <fcntl.h> // open 依赖
#include <unistd.h> // read/write/close 依赖
#include <string.h>
IO-OPEN/CLOSE
open 函数
int open(const char *pathname, int flags, mode_t mode);
- pathname: 文件的路径(如
"/dev/ttyS0"串口或"/home/pi/test.txt")。 - flags: 决定你怎么打开文件(最常用):
O_RDONLY: 只读打开。O_WRONLY: 只写打开。O_RDWR: 可读可写打开。O_CREAT: 如果文件不存在就创建它(通常配合O_WRONLY使用)。O_APPEND: 追加模式,写的数据会接在文件末尾。- mode: 仅在创建新文件(
O_CREAT)时有效,设置权限(如0644)。
返回值:
- 成功:返回一个正整数(fd)。
- 失败:返回
-1。
close 函数
int close(int fd);
fd: 就是 open 给你的那个整数。
注意:在嵌入式开发中,不关闭文件会导致“文件描述符泄漏”,程序运行久了就再也打不开任何设备了。
IO-read,write,lseek及mycopy的实现
read(fd, buffer, count)
- 作用:从文件描述符
fd指向的文件中,读取count个字节到内存buffer中。 - 嵌入式场景:读取传感器回传的原始字节。
write(fd, buffer, count)
- 作用:把内存
buffer里的count个字节写入到fd指向的文件/硬件设备中。 - 嵌入式场景:给电机驱动发控制指令。
lseek(fd, offset, whence)
- 作用:移动文件的“读写位置”。
- 嵌入式场景*:如果你在操作一个 Flash 存储芯片,你想直接跳到第 1024 字节处读取配置信息,就需要用到它。
系统IO操作嵌入式实战
#include <stdio.h>
#include <fcntl.h> // open 依赖
#include <unistd.h> // read/write/close 依赖
#include <string.h>
int main() {
// 1. 打开文件。如果不存在就创建它,权限设为 0644 (rw-r--r--)
int fd = open("sensor_data.bin", O_WRONLY | O_CREAT | O_APPEND, 0644);
// 2. 检查是否打开成功 (这是小白最容易漏掉的一步!)
if (fd == -1) {
perror("Open failed"); // 打印系统具体的错误原因
return 1;
}
// 3. 写入数据
const char *msg = "Sensor data: 25.5C\n";
ssize_t bytes_written = write(fd, msg, strlen(msg));
if (bytes_written == -1) {
perror("Write failed");
} else {
printf("成功写入了 %ld 字节\n", bytes_written);
}
// 4. 关闭文件
close(fd);
return 0;
}
详解标准IO与系统IO的应用差异
标准 I/O 能做,但系统 I/O 很难做的事
标准 I/O 强在数据转换和易用性。
- 格式化输入输出: 如果你想把一个整数
123变成字符串"123"存入文件。 - 标准 I/O:直接
fprintf(fp, "%d", 123);,一行搞定。 - 系统 I/O:你需要先调用
sprintf()把数字转成字符数组,然后再用write()写入。 - 跨平台开发: 标准 I/O 的代码在 Windows 和 Linux 下几乎通用。而系统 I/O(如
open的参数)在不同操作系统间差异巨大。
系统 I/O 能做,但标准 I/O 做不到的事
这正是嵌入式开发中最关键的部分。
- 非阻塞操作 (Non-blocking): 在操作串口或网口时,如果你希望“有数据就读,没数据立刻返回(而不是死等)”,你必须在
open()时使用O_NONBLOCK标志。标准 I/O 不支持这种底层细粒度的控制。 - 硬件特殊控制 (ioctl): 很多硬件操作(如设置串口波特率、调节风扇转速、配置 SPI 时序)需要用到
ioctl()系统调用。这个函数必须配合系统 I/O 的文件描述符fd使用,FILE *指针没法直接传给它。 - 原子性与实时性: 在多进程环境下,系统 I/O 的
write()通常是原子性的(即这一块数据写进去不会被别人打断)。而标准 I/O 因为有中间缓冲区,可能会出现数据碎片。