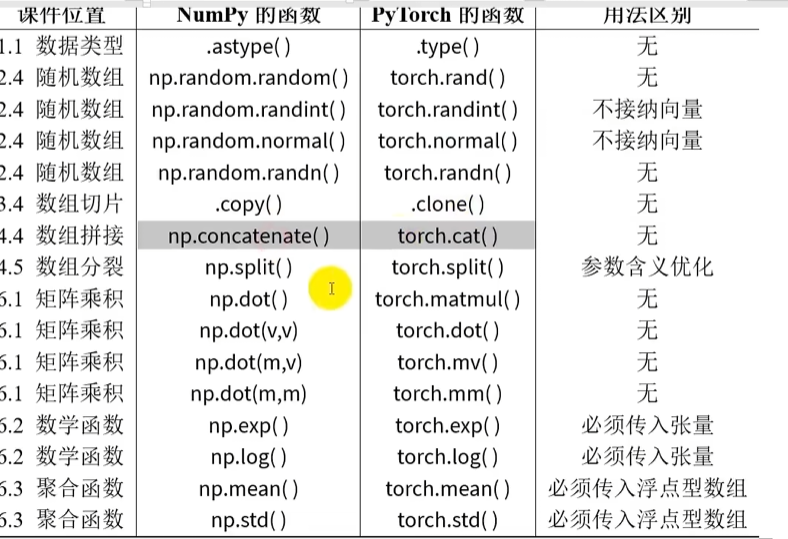
NumPy
一.数组的基础概念
导入NumPy 通常会起别名np
import numpy as np
数据类型
整数数组和浮点型数组
Python的数组每一个元素可以是不同的数据类型,但这需要为每一个元素都储存他的数据类型信息,造成内存浪费
而在Numpy中同一个数组只能容纳同一种数据类型避免了浪费. NumPy数组可简单分为整数型数组和浮点型数组
创建整数型数组:
arr1 = np.array( [1,2,3] )
print(arr1) :[1 2 3]
创建浮点型数组:
arr1 = np.array( [1.0,2,3] )
print(arr1) :[1. 2. 3.]
注意,使用print输出numpy数组后,元素之间没有逗号
同化定理
往整数型数组里插入浮点数,被插入浮点数会被自动截断为整数:

往浮点型数组里插入整数,被插入的整数会自动升级为浮点数:

共同改变定理
手动转换两种数据类型 - astype
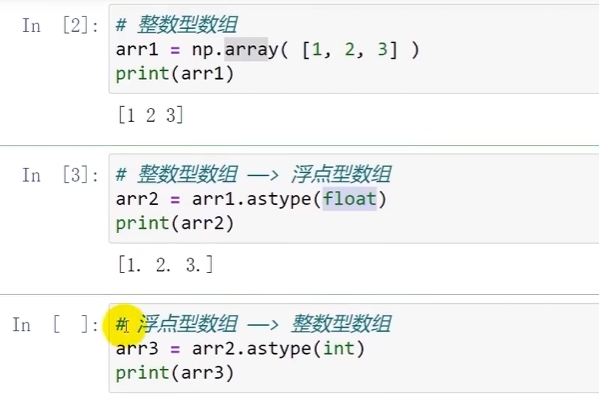
在计算中,有时浮点型和整数型会在不经意中转换
整数型数组遇到除法就会转换为浮点型数组:
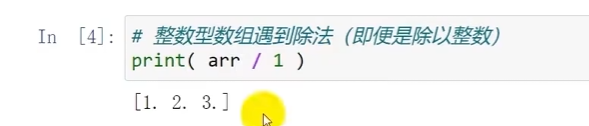
(原理:当一个数组÷一个常数,这个常数会作用在数组每一个元素上)
整数型数组和浮点型数组做计算会转换为浮点型数组:
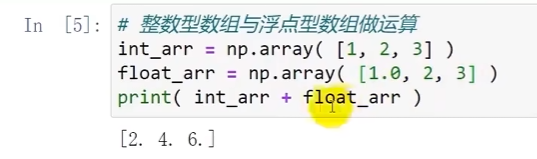
根据上述,整数型数组在计算中经常升级为浮点型数组,不过浮点型数组在运算中很少会降级整数型数组
数组维度
一维数组与二维数组

一维数组:()
二维数组:(())
三维数组((()))
数组的形状:
数组的形状(shape)指的是数组的维度和各个维度的大小-
查看方法:print(arr1.shape) #查看数组的形状
随时留意数组的维度,在进行拼接操作时需要数组是同维度的

一维数组(行参)
二维数组(行参,列参)
.....

演示:

不同维度数组之间的转换
方法.reshape(shape) 传入:形参,一维数组:传入一个值,二维数组:传入(行参,列参) 如果其中一个参数填-1则会自动计算
演示: 一维数组升级二维数组 (其中np.arange(10)代表一个0到9的数组)
传入参数(1,-1) 1是行参 -1是列参数 1代表一行 -1则代表根据行自动计算需要多少列
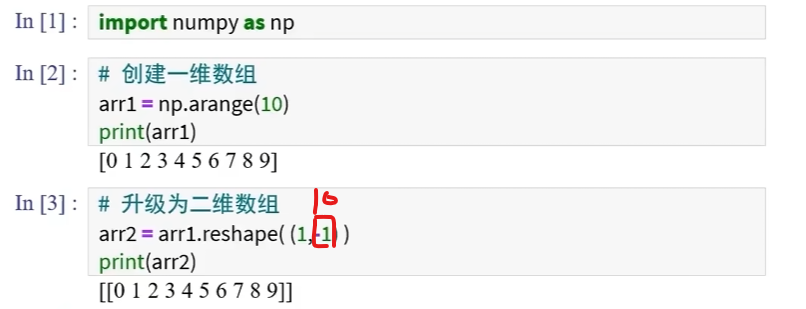
这里的-1是自动计算来的 如果手动填写10也可以
演示:二维数组降级一维数组 (np.arange(10)代表一个0到9的数组,reshape(2,5)是给它塑形成二维数组)
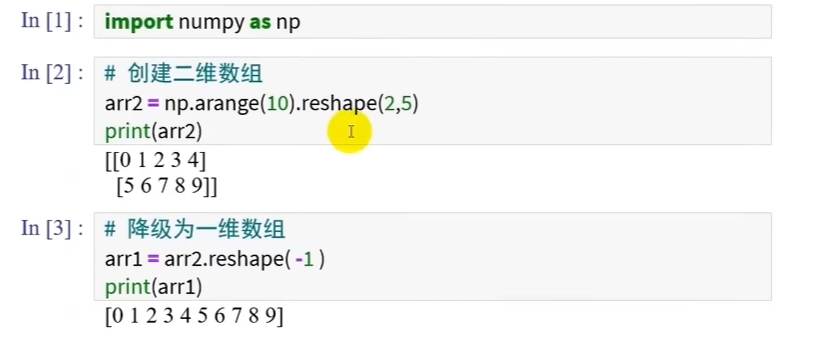
-1则代表自动填写
数组的创建
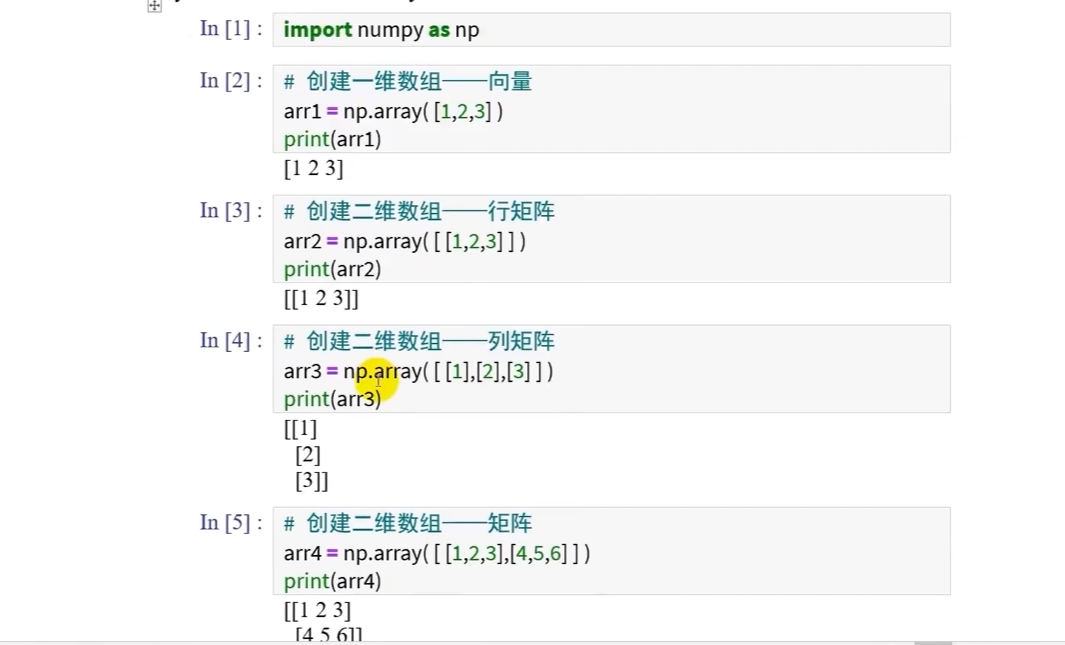
创建指定数组
当明确指导数组每个元素的具体数值时,可以使用np.array()函数,将python列表' [] '转换为nuppy数组
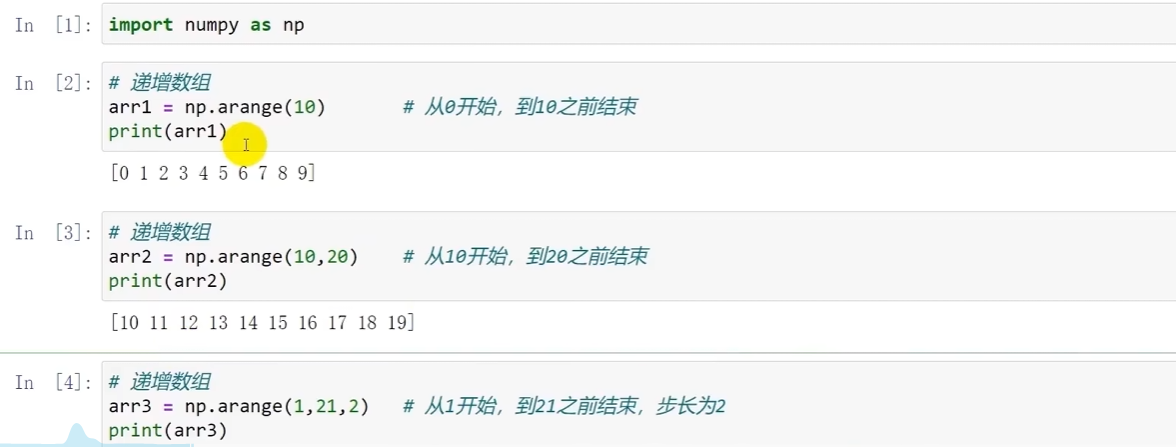
创建递增数组
np.arange()
创建同值数组
np.zeros()
np.ones()
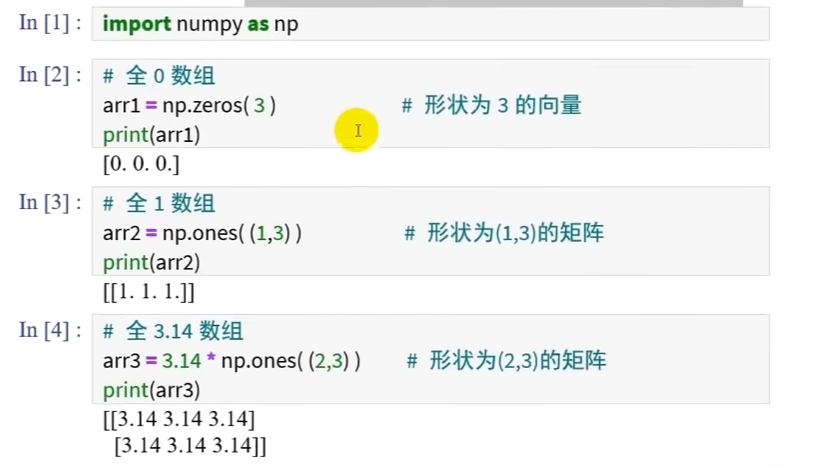
这两个函数输出的并不是整数型的数组 可能是怕被插进去的浮点数截断
创建随机数组
创建均匀分布的浮点型随机数组:
np.random (形状)

限制随机的区间:
例:创建一个60-100范围内均匀分布的3行3列随机数组 - (100-60)*np.random.randint(10,100(1,15))
创建均匀分布的整数型随机数组
np.randint (范围,范围,(形状))
(10-100 范围)

创建服从正态分布的随机数组:
np.normal(均值,标准差,(形状))
均值: 控制分布的“中心位置”
标准差: 控制分布的“分散程度”

正态分布:“中间多、两头少”
数组的索引
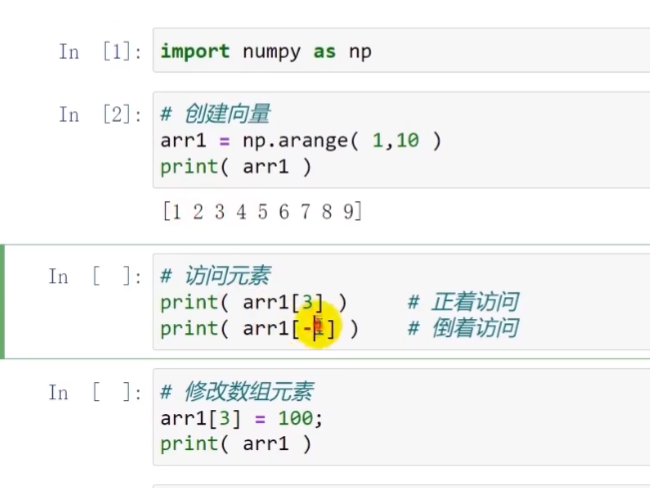
访问数组元素
与Python列表一致,访问Numpy数组元素时使用中括号,索引由0开始
对一维列表(向量)的使用
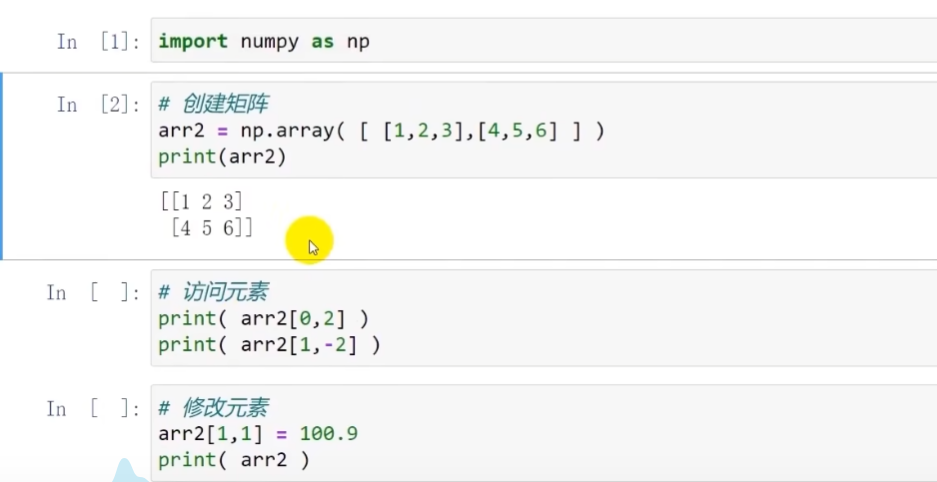
对二位列表(矩阵)的使用
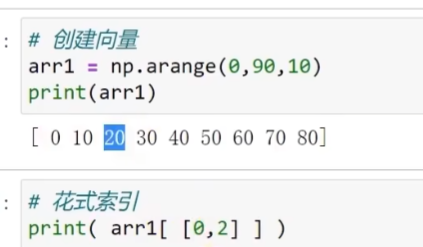
花式索引
用列表替代了普通索引的行列元素,并且输出仍是一个列表
用来 根据“数组或列表形式的索引”选取数据
import numpy as np
arr = np.array([10, 20, 30, 40, 50])
idx = [0, 2, 4]
print(arr[idx])
对一维列表的花式索引
需要两个中括号
对二维列表的花式索引

x y
访问数据切片
向量切片
列表(向量)的切片与Python原生例表的切片完全一致
索引方式: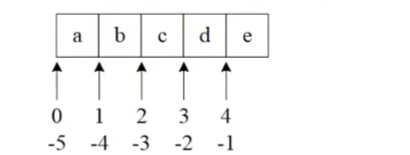
实例: 在0到9的向量中切片
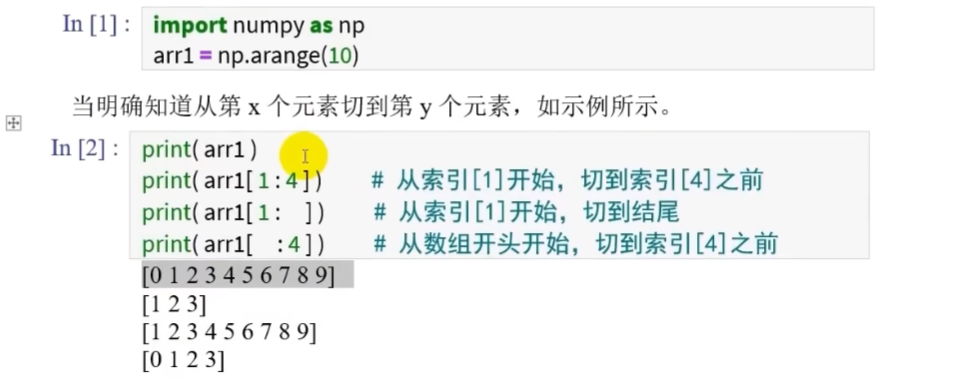
利用索引进行掐头去尾
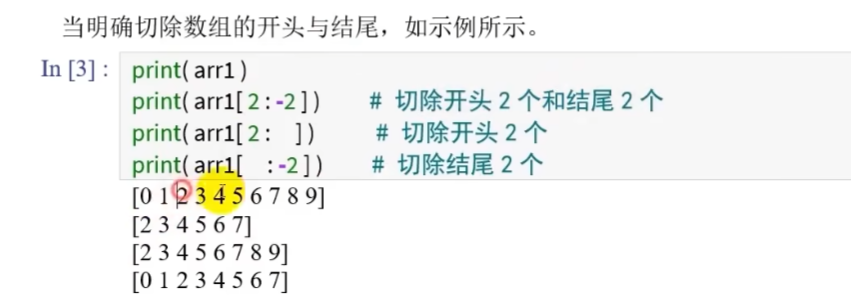
利用索引实现隔几个元素采样一次

矩阵的切片
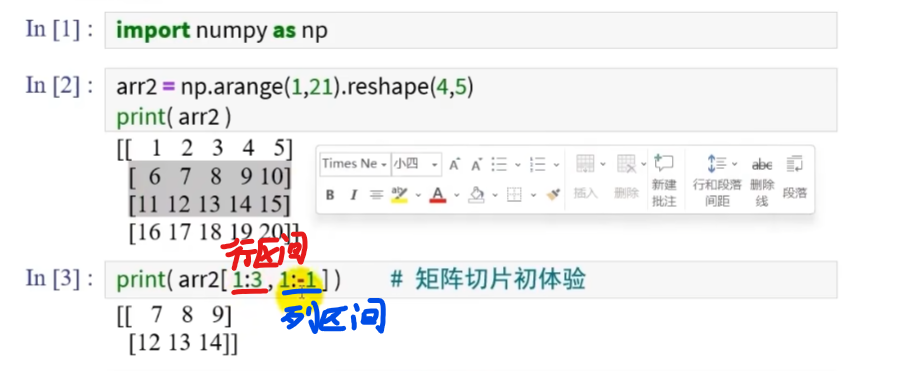
跳跃采样:
用切片提取矩阵的行

提取单独的一列出来数据的格式是向量格式
可以将向量转换回转换为行矩阵:

再将行矩阵转换列矩阵

在 NumPy 中,“行矩阵(row vector)”和“列矩阵(column vector)”本质上都是二维数组(
ndarray),它们的主要区别在 形状(shape)不同 (x,n)(n,x)
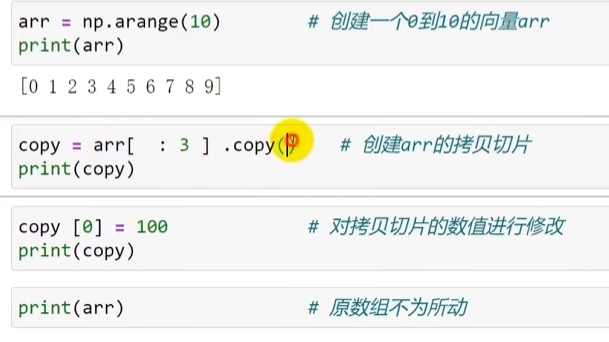
数组切片只是视图
切片得到的数组并不复制原数据,它只引用原数组的一部分内存。改变切片会影响原数组,反之亦然。
翻译:修改一个数组的切片中的元素,切片的原数组中的这个元素也会随之改变
如果需要为切片创建新变量(不受上述特性的影响) 则需要使用.copy方法
数组赋值仅是绑定
将Numpy数组完整的赋值给另一个数组也只是绑定,numpy数组之间的赋值不会创建新变量
和数组的切片情况一样,同样是用.copy可以不受特性影响
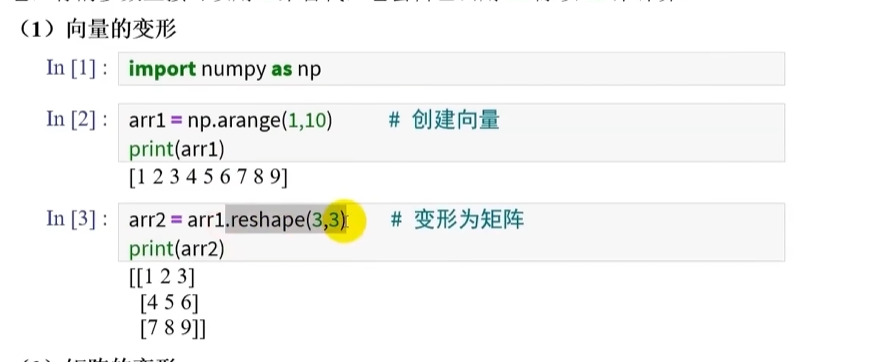
数组的变形
数组的转置
数组的转置主要是改变数组的轴重新排列
数组的转置方法为.T 只对矩阵(二维列表)有效 因此遇到向量(一位列表)要先将其转换为矩阵
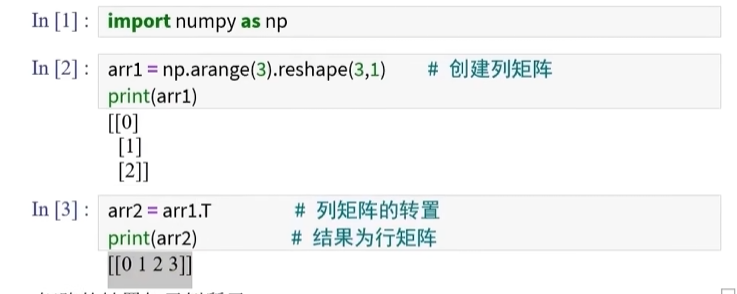
向量转换列矩阵
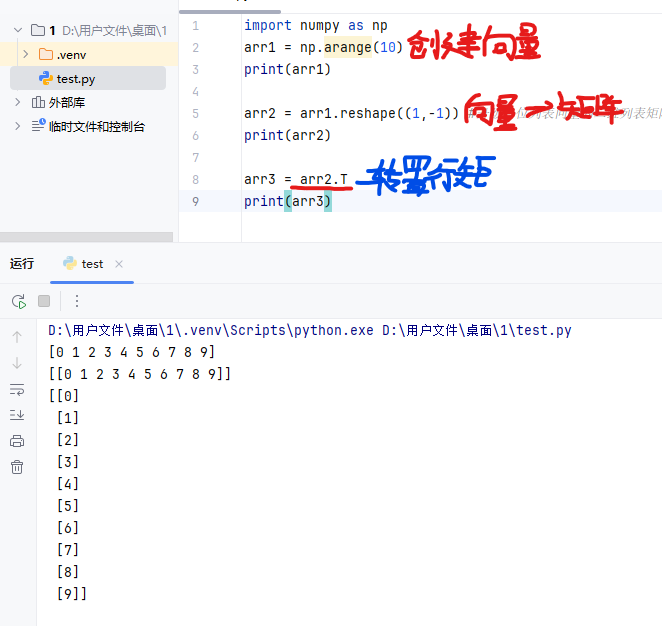
列矩阵转置行矩阵
数组的翻转
上下翻转: np.flipud()
左右翻转: np.fliplr()
向量翻转
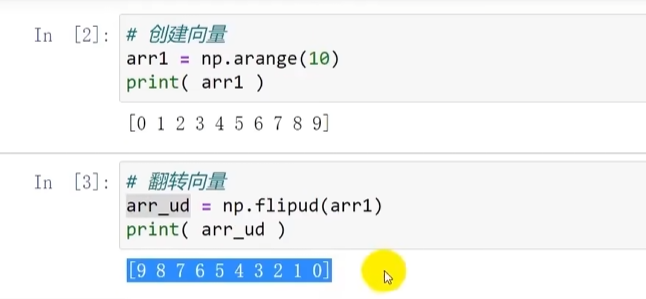
向量(一维列表)只能进行你上下翻转
数组翻转
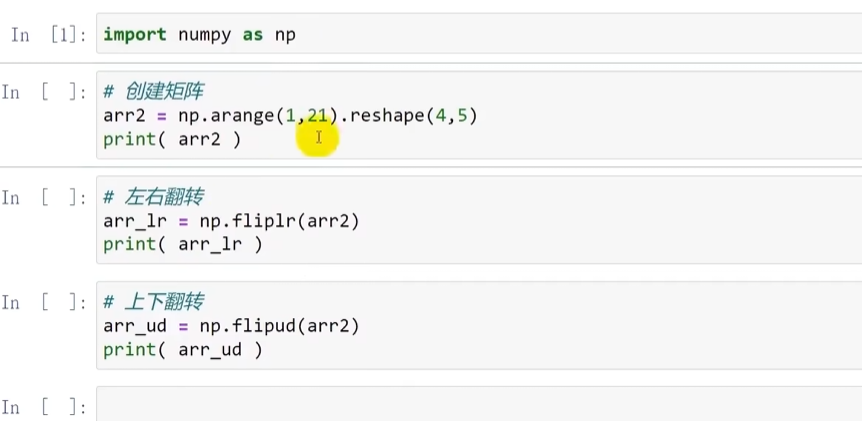
数组的重塑
想要重塑数组的形状,需要用到.reshape(重塑的形状)方法
向量的变形
矩阵的变形

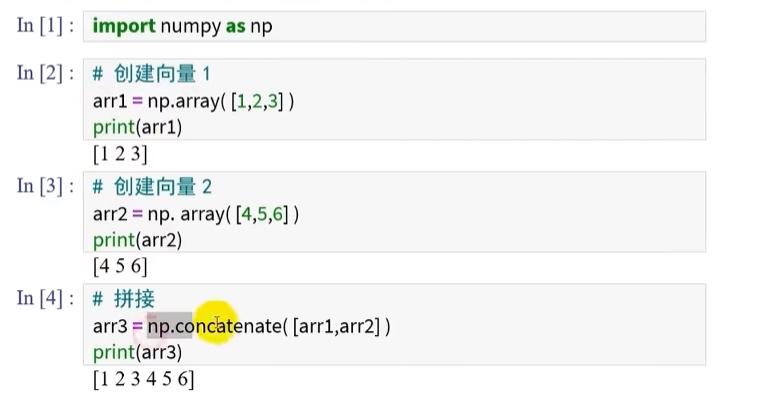
数组的拼接
向量的拼接
两个向量的拼接将获得一个加长版的向量
np.concatenate([arr1,arr2])
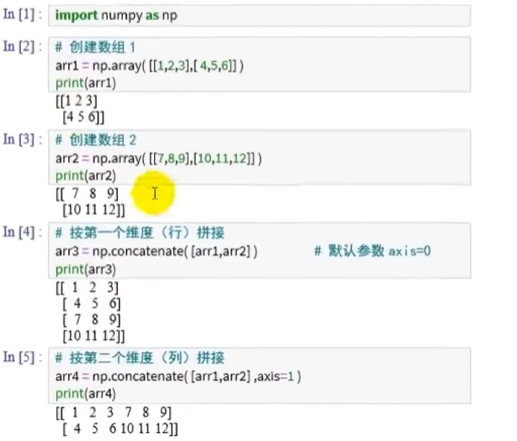
矩阵的拼接
np.concatenate([arr1,arr2],axis=0) #默认参数0 行拼接 参数1 列拼接
数组的分裂
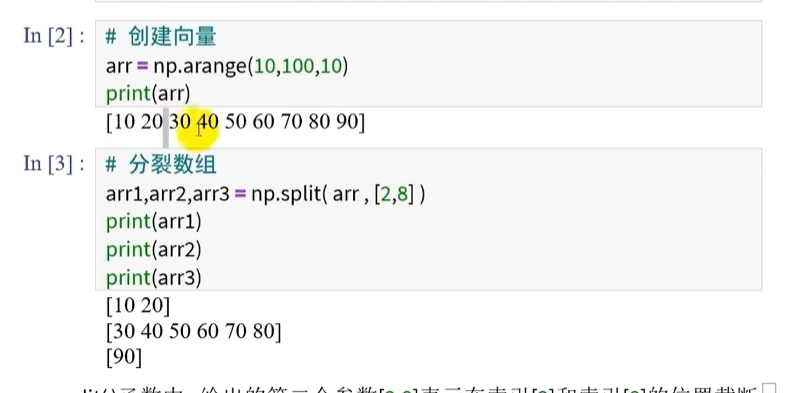
向量的分裂
向量分裂,将得到若干个更短的向量
参数: [2,8]:分开的位置
矩阵的分裂
把一个矩阵分裂成多个矩阵
按维(行)度进行 且分裂出来还是矩阵
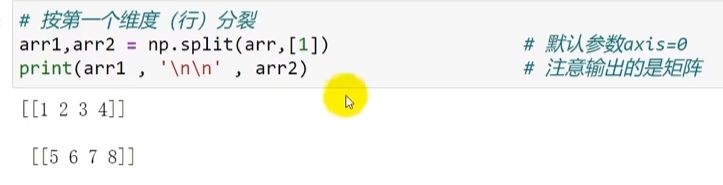
按第一个维度(行)分裂 参数axis=0(可以不填)
按第二个维度(列)分裂 参数设定axis=1

数组的运算

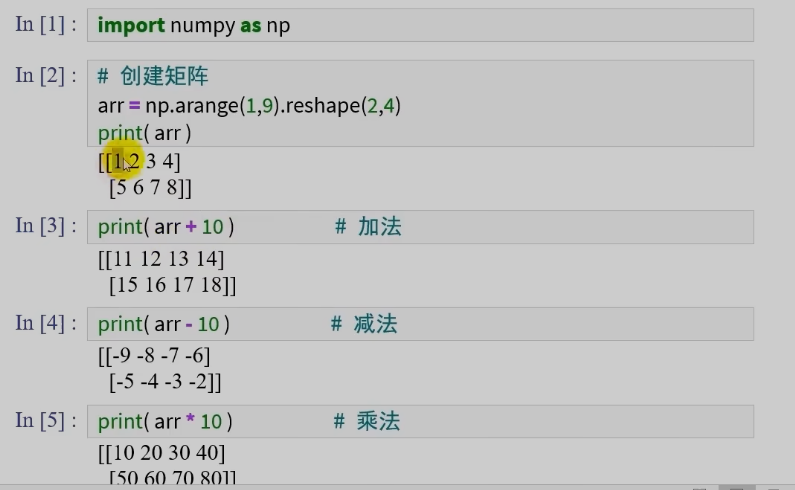
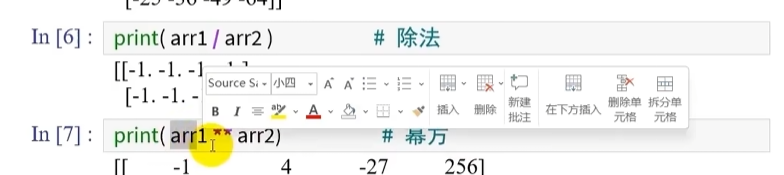
数组与系数的运算
当矩阵和一个系数发生运算, 这个系数会作用到矩阵的每一个元素
并且计算完成后会改变成浮点型数组

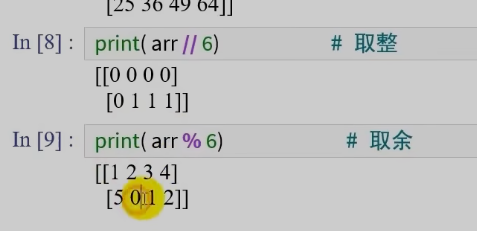
数组与数组之间的运算
同纬度数组间的运算是逐元素计算

广播
不同形状数组之间的运算
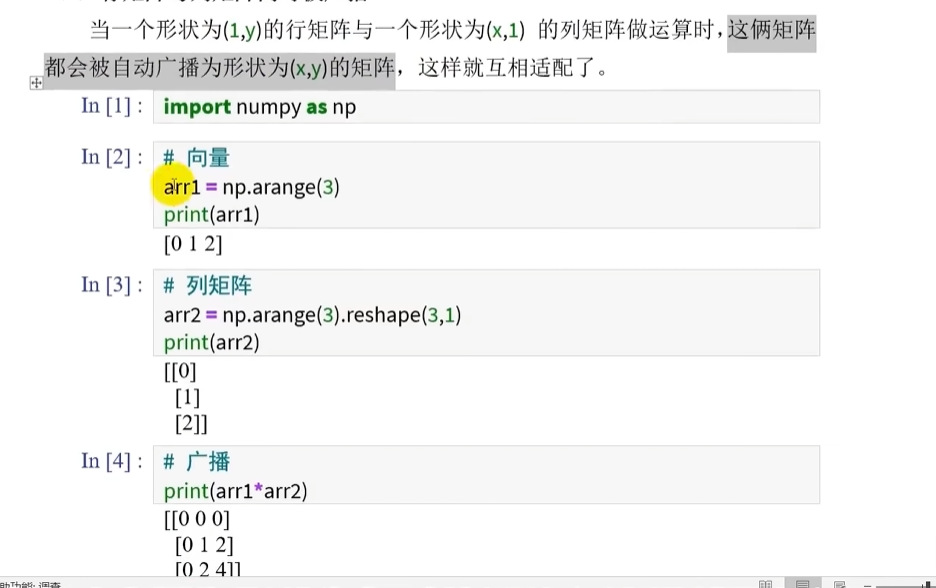
规则: 当向量和矩阵运算的时候,向量会自动升级成行矩阵
如果某矩阵是行矩阵或列矩阵,则其被广播,以适配另一个矩阵的形状
广播:广播行矩阵/列矩阵其中维度为1的那个维度
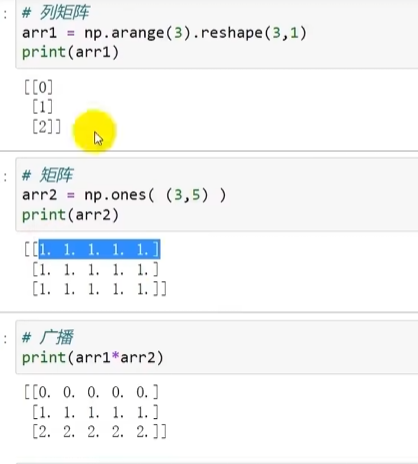
向量被广播:
原理:向量转换为行矩阵,并按列广播(行矩阵同理)
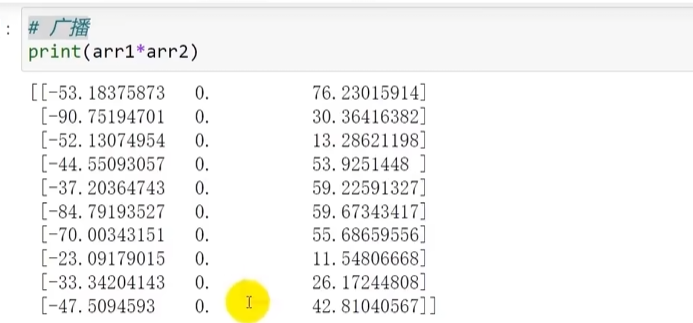
列矩阵被广播:
列矩阵计算时会按照水平方向进行广播
行矩阵和列矩阵同时被广播:
行矩阵和列矩阵同时向两侧广播.
计算原理: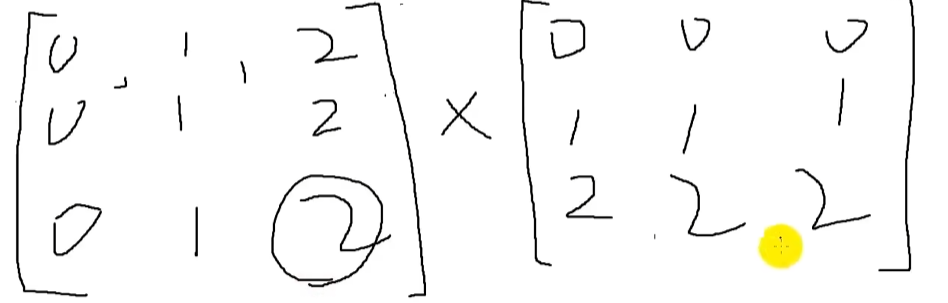
数组的函数
矩阵乘积
向量和矩阵的乘积

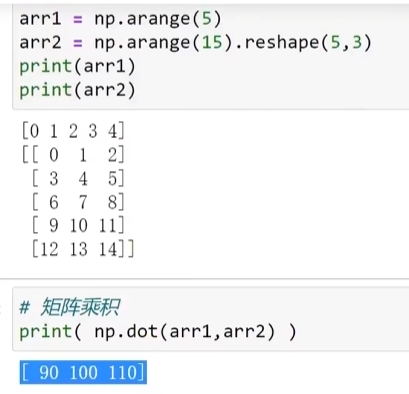
矩阵和向量的乘积


矩阵与矩阵的乘积

数学函数
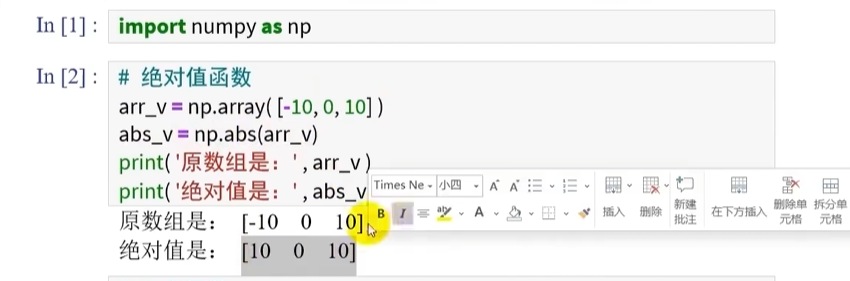
取绝对值
np.abs()
三角函数
求正弦值:sin_v
求余弦值:cos_v
求正切值:tan_v

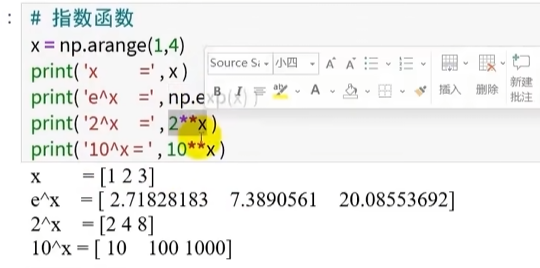
指数函数
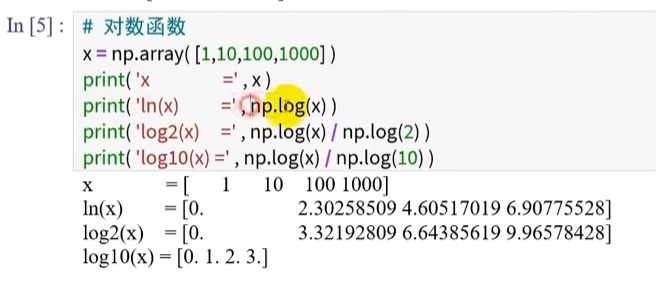
对数函数
聚合函数
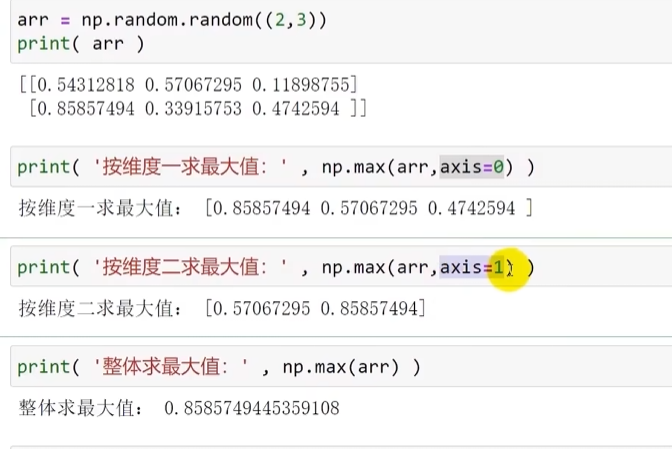
在矩阵中求最大值
axis=0时为一维度(纵向)
axis=1时为一维度(横向)
在矩阵中求和
axis=0时为一维度(纵向)
axis=1时为一维度(横向)

再矩阵中求均值和标准差
axis=0时为一维度(纵向)
axis=1时为一维度(横向)

聚合函数的安全版本,忽略缺值

布尔型数组
用处:用 True/False 来选择、过滤、索引或操作数据。
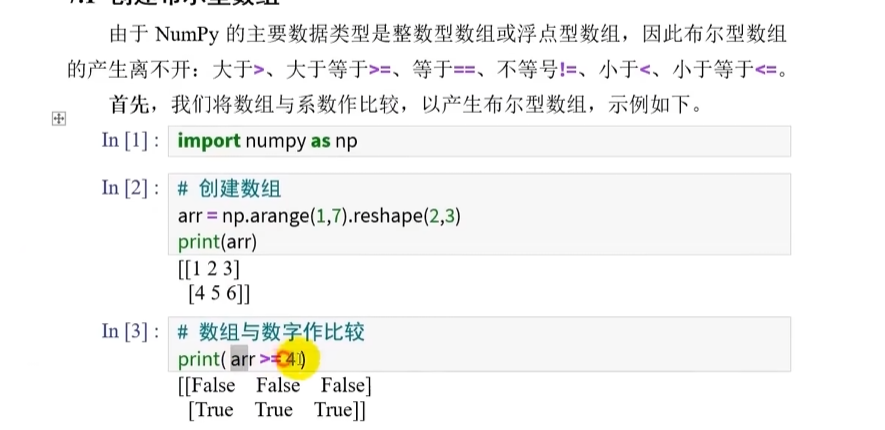
创建布尔型数组
将数组与系数比较,产生布尔数组
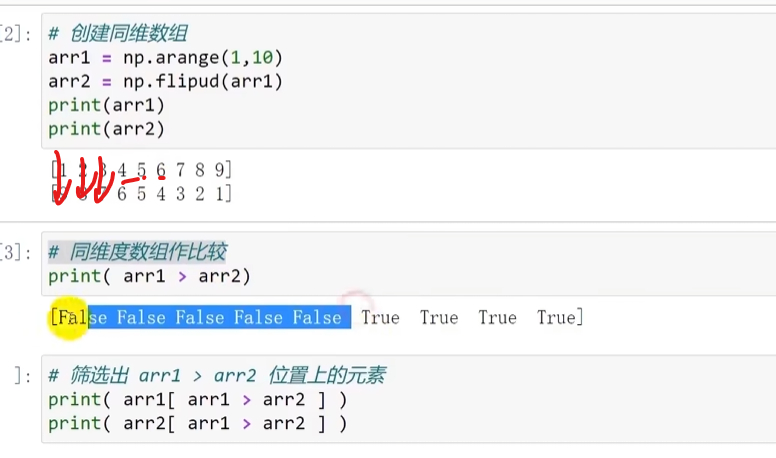
同纬度数组作比较,产生布尔数组

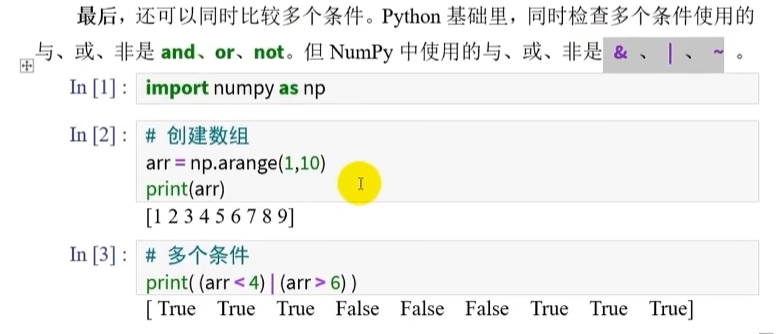
多个条件比较
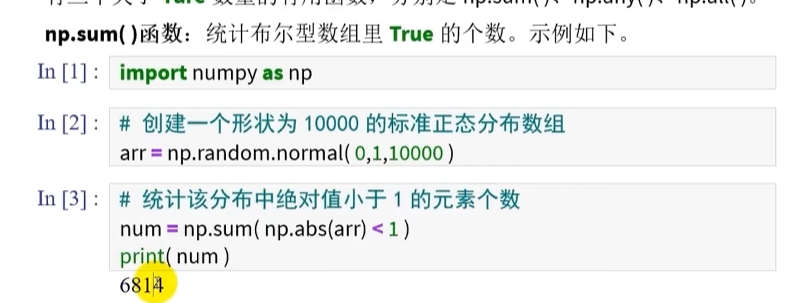
布尔型数组中True的统计
统计True出现的次数
np.sum()
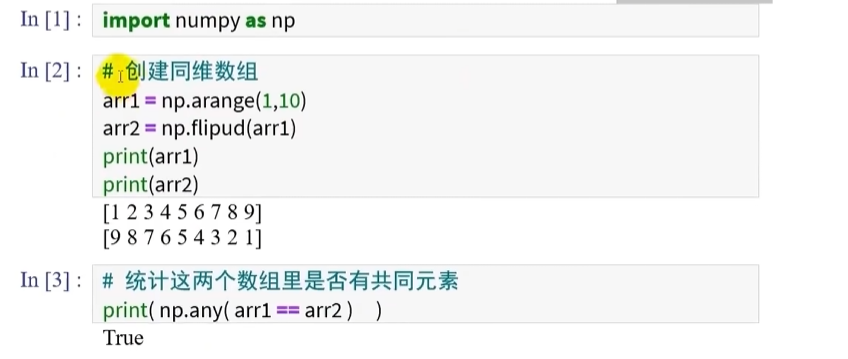
统计两个数组中是否有共同元素
np.any()
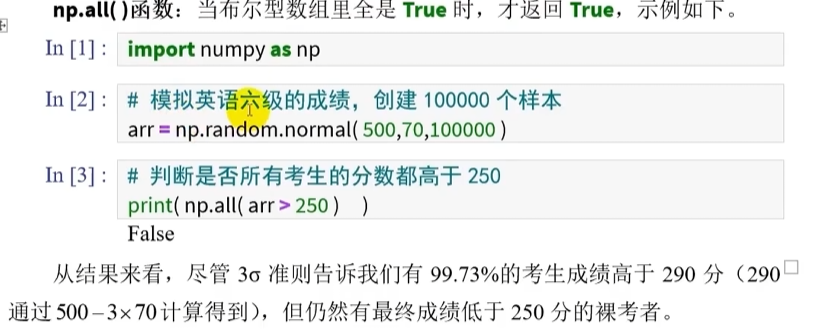
统计布尔型数组中是否全是True
np.all()
布尔型数组作为掩码

筛选出数组中大于小于或等于某个数字的元素
把布尔型数组放在索引位置 ,会索引出满足布尔条件的元素

筛选出数组逐元素比较的结果
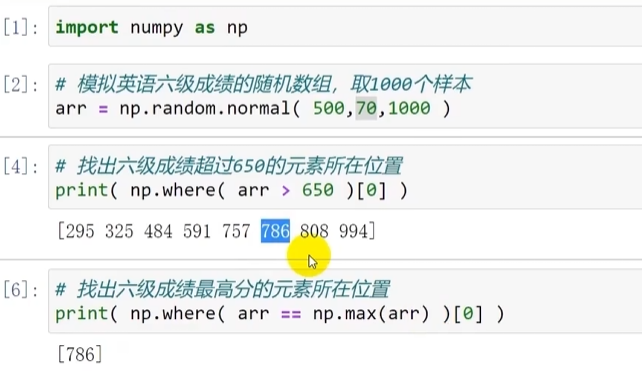
找到满足条件的元素所在位置
想找到一个很长的数组中符合某个条件的元素们所在的索引位置
np.where()
np.where输出的内容是一个元组 输出的第一个内容时数据本身 后面的内容是类型 所以取数据[0]
从数组到张量