机器学习简介
机器学习(ML):
从数据中自动分析获取模型,并利用模型对未知数据进行预测
机器学习的类型
机器学习主要分为以下三种类型:
1. 监督学习
训练数据是带有标签的,即每个样本都带有正确答案
定义: 监督学习是指使用带标签的数据进行训练,模型通过学习输入数据与标签之间的关系,来做出预测或分类。应用: 分类(如垃圾邮件识别)、回归(如房价预测)。
例子: 线性回归、决策树、支持向量机(SVM)。
预测离散数据: 分类
预测连续的数值: 回归
线性回归
用于分析自变量与因变量之间的关系
线性回归含义:
线性 是指 因变量(目标变量) 与 自变量(特征变量) 之间的关系可以通过一条直线来表示
回归 是一种统计方法,主要用于 预测 或 估计 一个连续变量(因变量)与其他变量(自变量)之间的关系。
线性回归训练原理解析:
https://www.bilibili.com/video/BV1ZgGczmEoU?vd_source=0cf0b8e7c14199f1cfb6ba5253cb48d8&spm_id_from=333.788.videopod.sections

根据已有的自变量和因变量构建一个坐标系. 如图,其中每个点的坐标都是(自变量,因变量)
这时在其中找到一条最能拟合这些点的直线,这条直线就代表这些自变量和因变量的关系. (总结了自因变量变化的规律)
(也就是说找到可以用来解释现在自变量与因变量的关系,或者用于根据自变量预测一个符合这个规律的因变量)

这条直线的公式是Y=MX+C X是自变量,Y是因变量,系数M是直线的斜率,C是直线的截距(直线与Y轴交点的高度).
开始推导这条直线: 先随机选取一条直线(这条直线就是预测值),然后测算每个数据点到该直线的距离

这些点和直线间的距离就是这些实际值与直线预测值的误差值
之后将这些误差值每个都平方后再求平均得到均方误差MSE (均方误差就是损失函数)

通过不断调整系数M 直线的斜率和系数C直线的截距,来使这条直线离这些数据点的平均距离越来越小,让均方误差MSE越来越低,达到预测更准确的效果(之所以是用均方误差控制而不是直接用距离误差控制是因为均方误差对大偏差惩罚更严格)
到一定成都后就训练完成了,之后会用测试集验证,测试其对新数据的预测能力
最后:线性回归模型中的R2: R2=1−总平方和(TSS)残差平方和(RSS),是一个衡量模型拟合优度的统计量,用来表示模型的解释能力
注释: 梯度下降 - 一种优化工具,引导我们不断让直线贴合数据的理想值
多特征场景(多个数值找关系,多维度)就是单特征场景的延申,底层逻辑一样
决策树
支持向量机(SVM)
2. 无监督学习(Unsupervised Learning)
发现数据中内在的 隐藏的模式和结构
数据 只有特征,没有标签,模型要自己发现规律。
定义: 无监督学习使用没有标签的数据,模型试图在数据中发现潜在的结构或模式。
应用: 聚类(如客户分群)、降维(如数据可视化)。
例子: K-means 聚类、主成分分析(PCA)。
聚类:将数据分成不同的组,组内的数据彼此相似. 例如客户分群 新闻主题分组
降为:在保留重要信息的同时,减少数据的变量数量,使其更容易可视化和处理
K-Means
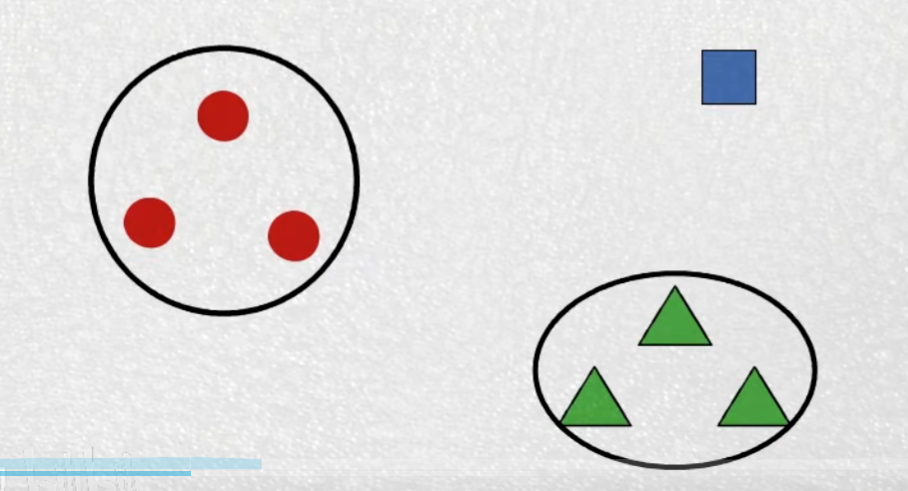
原理:将相似的样本归为一类,并用这几个样本的中心位置表示这个类别,以便新样本的加入
每当有新样本加入都会改变这个类别的中心位置,来适应新样本
距离越近代表两个样本点相近
常见参数:
n_clusters(K)
含义:要分成多少个簇 作用:直接决定聚类结果
init
含义:初始质心的选择方式
max_iter
含义:单次运行的最大迭代次数
n_init
含义:用不同初始质心跑多少次,选最好的结果
层次聚类
DBSCAN
3. 强化学习(Reinforcement Learning)
智能体通过与环境不断交互,根据其行动获得奖励或呈高发来学子最佳策略,类似训练动物
定义: 强化学习通过与环境互动,智能体在试错中学习最佳策略,以最大化长期回报。每次行动后,系统会收到奖励或惩罚,来指导行为的改进。 应用: 游戏AI(如AlphaGo)、自动驾驶、机器人控制。 例子: Q-learning、深度Q网络(DQN)。
4.深度学习(DL)
深度学习是机器学习的一个子领域,它通过构建和训练多层神经网络(即“深度神经网络”)来进行数据分析和预测。深度学习能够自动从数据中提取特征,而不需要人为地指定特征。
深度学习模型非常复杂,通常包含多层神经网络,每一层可以学习到数据的不同层次特征。它们在处理大量数据时表现出色,尤其适用于图像、语音、文本等非结构化数据。