Pandas
Pandas 基本信息
1.pandas简介
pandas 是 python数据分析工具链中最核心的库
充当数据读取 清洗 分析 统计 输出的高效工具
pandas提供了易于使用的数据结构和数据分析工具.特别适用于处理结构化数据.(例如表格等)
pandas是基于Numpy构建的专门为处理表格和混杂数据设计的Python库,核心设计理念:
标签化数据结构,提供带标签的轴
灵活处理缺失的数据,内置NAN处理机制
智能数据对其:自动按标签对齐数据
强大io工具:支持从CSV exvel Sql等数据源读取数据
时间序列处理:原生支持日期时间处理和频率转换
2.pandas可以对数据的处理
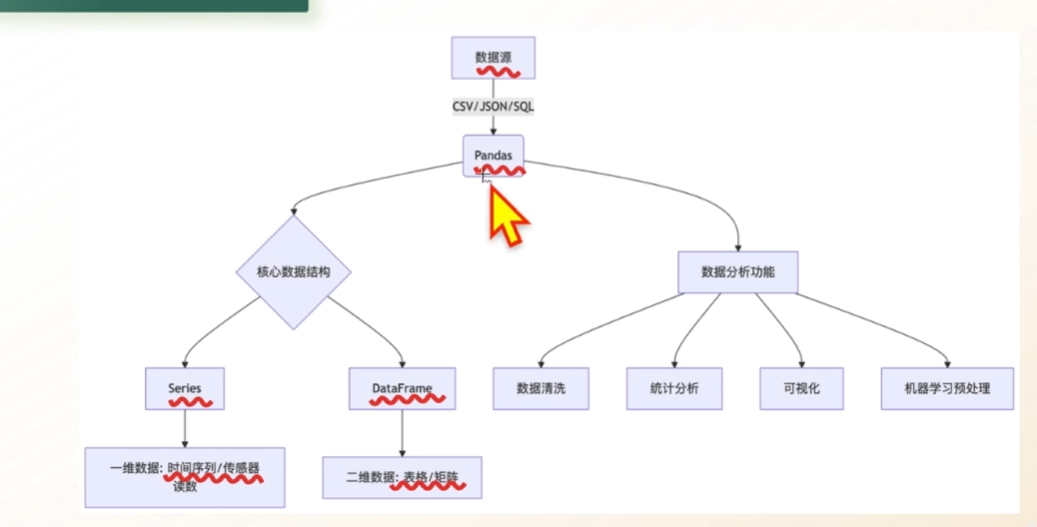
3.pandas的两种数据类型
4.引入Pandas库
import pandas as pd
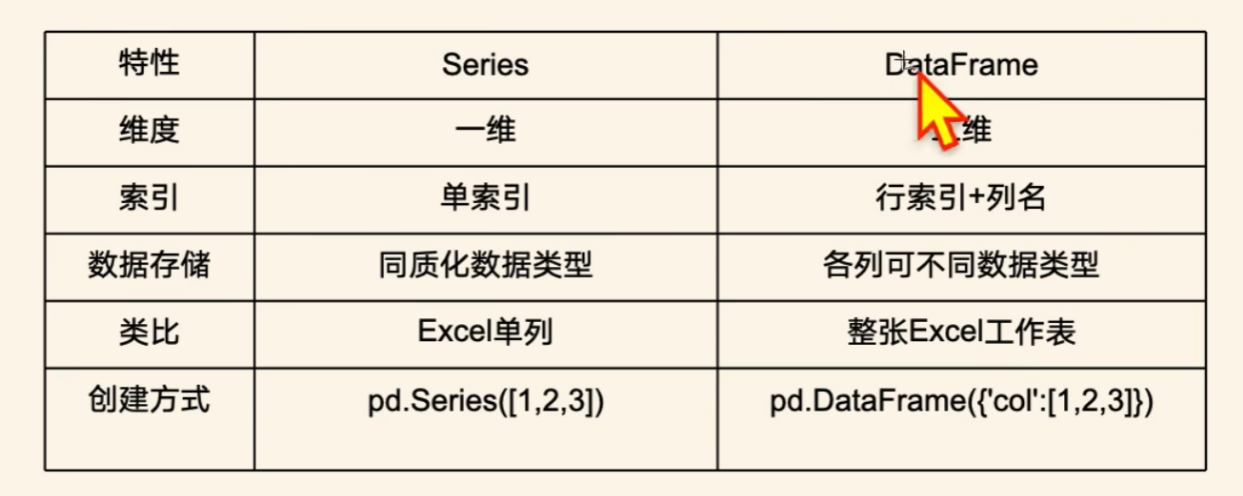
Pandas Series数据结构
Series是Pandas中的一种基础数据结构,包含名称,索引,和具体内容
series类似比一列,是一种一维列表
创建Series数据
传入列表创建series
要创建的series名 = pd.Series([数据,列表格式],参数)
s = pd.Series([1,2,3,4,5,6,7,8,9]) #创建一个名为s的series,并填入数据,数据是一个列表
print(s) #输出这个series
 将创建的Series输出,输出的左侧是索引,右侧是数值. 最后一列会显示数据的类型
将创建的Series输出,输出的左侧是索引,右侧是数值. 最后一列会显示数据的类型
自定义Series索引
参数: index[自定义的索引,列表格式]
s = pd.Series([1,2,3,4,5,6,7,8,9,10],index=['a','b','c','d','e','f','g','h','i','j'])

自定义Series标签
标签作用:标注这个series的所存的数据的用处
参数: name = '名称'
s = pd.Series([1,2,3,4,5],index=['a','b','c','d','e'],name='名称')

传入字典创建Series
= pd.Series({'索引':数值 })
s = pd.Series({"a": 1, 'b':2, 'c':3 })
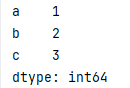
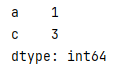
创建Series时,从已有Series中用索引取值
= pd.Series(已有Series,index=[索引])
s = pd.Series({"a": 1, 'b':2, 'c':3 })
s1 = pd.Series(s,index=['a','c'])
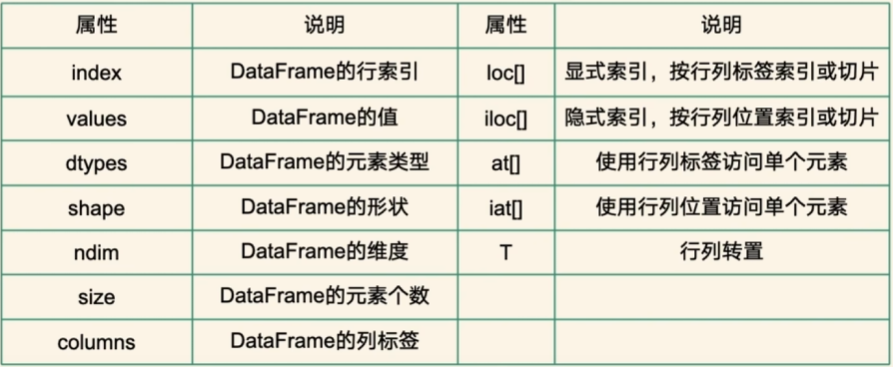
Series属性
备注:shape - 形状,几行几列
ndim - 维度,因为series就是一个一维度的列表,所以取出值为1
再属性中,例如loc[],at[]都是显式索引,而在前面加i的时隐式索引.(
显式索引 : 由用户指定或 Pandas 创建的标签 (Label) ),
隐式索引 : 元素在 Series 中的整数位置 (Position),从 0 开始。)
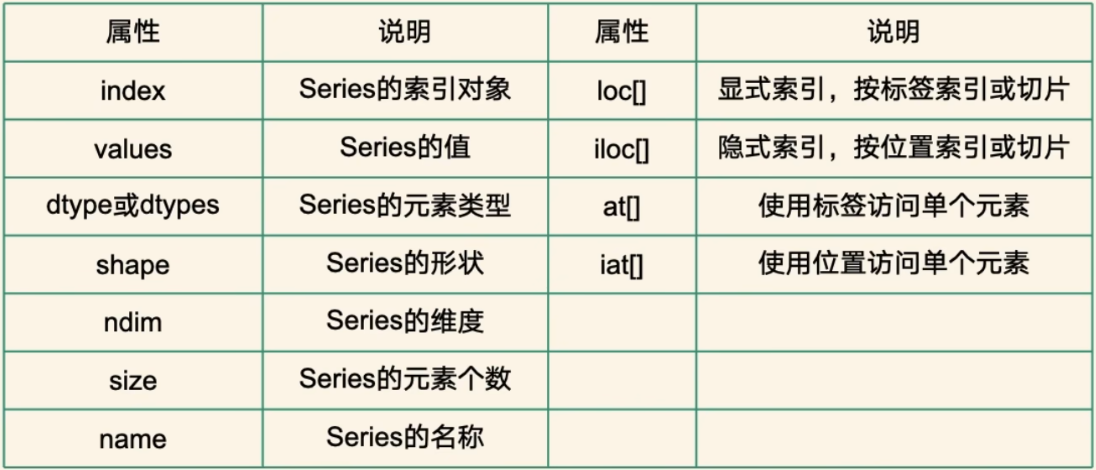
index
Series的索引对象
s = pd.Series(['1','2','3'],index=['a','b','c'])
print(s.index)
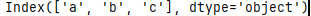
values
series的值
s = pd.Series(['1','2','3'],index=['a','b','c'])
print(s.values)
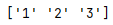
dtype或dtypes
series的元素类型
print(s.dtype)
print(s.dtypes)

shape
series的形状
s = pd.Series(['1','2','3'],index=['a','b','c'])
print(s.shape)
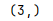
ndim
Series的维度
s = pd.Series(['1','2','3'],index=['a','b','c'])
print(s.ndim)
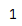
size
series中的元素个数
s = pd.Series(['1','2','3'],index=['a','b','c'])
print(s.size)

name
series的名称
s = pd.Series(['1','2','3'],name='test')
print(s.name)

索引相关
loc[]
获取索引位置(显示索引(自定义的索引)对应的位置)
s = pd.Series(['1','2','3'],index=['A','B','C'])
print(s.loc['A'])
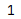
iloc[]
获取索引位置(隐式索引(从0开始从头往后的默认索引)对应的位置)
s = pd.Series(['1','2','3'],index=['A','B','C'])
print(s.iloc[0])
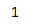
利用索引切片
无论是显式索引还是隐式索引都可以进行切片
s = pd.Series(['1','2','3'],index=['A','B','C'])
print(s.iloc[0:2])
print(s.loc['A':'C'])

at[]
获取单个显示索引位对应的数值
s = pd.Series(['1','2','3'],index=['A','B','C'])
print(s.at['A'])
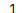
iat[]
s = pd.Series(['1','2','3'],index=['A','B','C'])
print(s.iat[0])
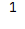
Series访问数据
索引取值
上文中的loc[] / iloc / at /iat都是索引取值的方法之一
常规取值方法
方法:series加大括号'[ ]' 括号里可以索引显式也可以是隐式
s = pd.Series(['1','2','3'],index=['A','B','C'])
print(s[0])
print(s['A'])
布尔索引
在numpy中有类似的用法
例:用筛选出s中小于3的数值
s = pd.Series([1,2,3,4,5])
print(s[s<3])
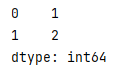
取头部
取头部信息(前x行数据)
.head(打印的行数) #不填参数时默认后5行
s = pd.Series([1,2,3,4,5,6,7,8,9,10])
print(s.head())
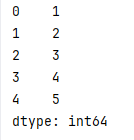 ****
****
取尾部
取尾部信息(后x行数据)
.tail #不填参数时默认后5行
s = pd.Series([1,2,3,4,5,6,7,8,9,10])
print(s.tail())

Series常用方法
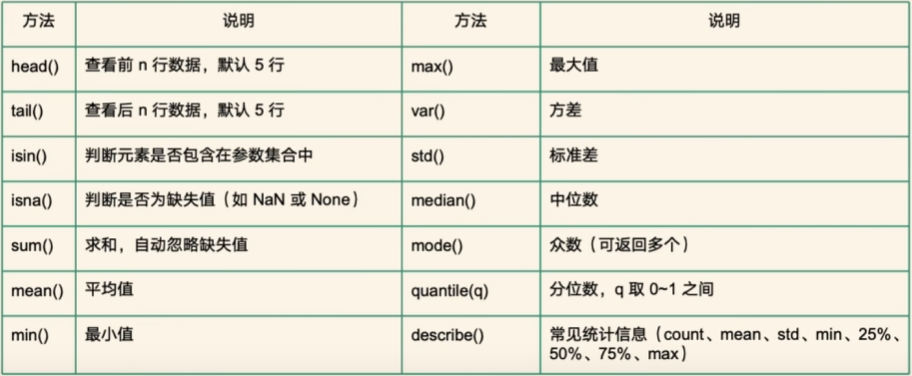
isin
.isin([数值]) 判断series中是否包含[]中的数值
判断元素是否包含在集合里,返回True/Flase
s = pd.Series([1,22,32,4,np.nan,6,7,8,None,10])
print(s.isin([4])) #判断s中是否有4这个数值
 返回效果:索引+布尔值
返回效果:索引+布尔值
isna
.isna()
判断元素是否为缺失值 判断缺失值
s = pd.Series([1,22,32,4,np.nan,6,7,8,None,10])
print(s.isna())
 返回效果:索引+布尔值
返回效果:索引+布尔值
sum
求和,自动忽略缺失值
mean
.mean()
平均值
s = pd.Series([1,10,30,40,25,21])
print(s.mean())
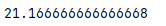
min
.min()
最小值
s = pd.Series([1,10,30,40,25,21])
print(s.min())
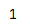
max
最大值
s = pd.Series([1,10,30,40,25,21])
print(s.max())
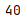
var
.var()
方差
s = pd.Series([1,10,30,40,25,21])
print(s.var())
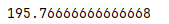
std
.std()
标准差
s = pd.Series([1,10,30,40,25,21])
print(s.std())
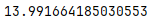
median
.median()
中位数
s = pd.Series([1,10,30,40,25,21])
print(s.median())
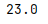
mode
众数,可返回多个
s = pd.Series([1,2,3,4,5,10,9,8,7,6,6,6])
print(s.mode())
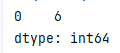
quantile
.quantile()
获取其他分位数
s = pd.Series([1,2,3,4,5,10,9,8,7,6])
print(s.quantile(0.25))
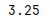
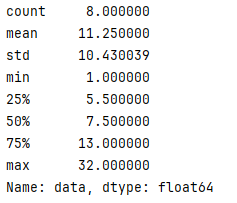
describe
.describe()
查看所有描述性的信息,如常见统计信息,count mean std min 20%,75% max
count: 计数
mean: 平均值
std: 标准差
25%,50%,75%: 分位数
s = pd.Series([1,22,32,4,np.nan,6,7,8,None,10],index = ['A','B','C','D','E','F','G','H','I','J'],name='data')
print(s.describe())
value_counts
每个唯一值的出现次数(计数)
s = pd.Series([1,2,3,4,5,10,9,8,7,6,6,6])
print(s.value_counts())

count
.count()
获取一个series中的元素个数(忽略缺失值)
s = pd.Series([1,22,32,4,np.nan,6,7,8,None,10])
print(s.count())
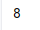
nunique
获取去重之后的元素个数
s = pd.Series([1,2,3,6,6])
print(s.nunique())

unique
.unique() 和其他去重方式不同的是,它会返回一个普通列表而不是series
获取去重之后的数组(去重)
s = pd.Series([1,2,3,6,6])
print(s.unique()
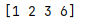
drop_duplicates
.drop_duplicates()
去除重复项,如果有多个缺失值会只保留一个缺失值
s = pd.Series([1,2,3,6,6])
print(s.drop_duplicates())
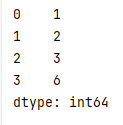
sample
随机抽样
sort_index
.sort_index()
按索引排序
参数ascending ,true升序,false降序
sort_values
.sort_values()
按值排序
replace
替换值
keys
.keys()
获取索引 返回series的索引对象
s = pd.Series([1,22,32,4,np.nan,6,7,8,None,10],index = ['A','B','C','D','E','F','G','H','I','J'],name='data')
print(s.keys())
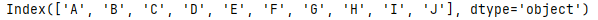
和.index效果一样,但keys()是方法,index是属性
s = pd.Series([1,22,32,4,np.nan,6,7,8,None,10],index = ['A','B','C','D','E','F','G','H','I','J'],name='data')
print(s.index)
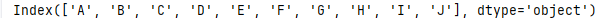
NAN
在Series中,缺失值np.nan , None等都会显示Nan
s = pd.Series([1,22,32,4,np.nan,6,7,8,None,10],index =['A','B','C','D','E','F','G','H','I','J'])
print(s)
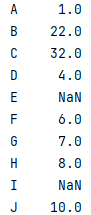
Series案例
对Series数据的分析
学生成绩统计
创建一个包含10名学生数学成绩的series,成绩范围在50-100之间. 计算平均分 最高分 最低分 并找出高于平均分的学生人数
import pandas as pd
import numpy as np
from pandas import Series
np.random.seed(42) #用种子控制生成的随机数组(可以使在每次运行生成的数组一致)
scores = pd.Series(np.random.randint(50,101,10), index=['学生'+str(i) for i in range(1,11)])
#创建series 填入内容使用np随机生成的满足上述要求的数组 设置索引为学生1.学生2.学生3......学生11
print('平均分:',scores.mean())
print('最高分:',scores.max())
print('最低分:',scores.min())
#找到高于平均分的学生人数
mean = scores.mean() #取平均分
print('高于平均分的学生人数',scores[scores>mean].count())
# 布尔索引,Scores>mean返回的值是索引--True/False 在外面加上scores[]来实现只取其为True的值
#.count是计数,用来统计过滤出来的满足条件的学生有多少个
温度数据分析 - diff求临近两元素差值
给定某城市最高温度Series,找出温度超过30度的天数,计算平均温度,找出温度变化最大的两天
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
temperatures = pd.Series([28,31,29,32,30,27,33],
index=['周一','周二','周三','周四','周五','周六','周日'])
#找出温度超过30度的天数
print('温度高于三十度的天数:',temperatures[temperatures>30].count()) # 布尔索引
#计算平均温度
print('平均温度: ',temperatures.mean())
#将温度从低到高排序
temperatures = temperatures.sort_values(ascending=False) #参数ascending:是否升序
print('从高到低排序',temperatures)
#找出温度变化最大的两天
t3 = temperatures.diff().abs() #abs 取绝对值
#diff方法 找到Series数组中每两个元素之间的差值 ,因为第一个元素之前没有元素,所以第一个值是NAN
print('温度变化最大的两天:',t3.sort_values(ascending=False).keys()[:2].tolist())
# 给取到的差值绝对值排序,并用索引切片前两个,再转换成列表
股票价格分析 -- pct_change求临近两元素涨幅百分率

import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
prices = pd.Series([102.3,103.5,105.1,104.8,106.2,107.0,106.5,108.1,109.3,110.2], index=pd.date_range('2023-01-01', periods=10))
#计算每日收益率
ss = prices.pct_change() #percent 百分率变化方法 计算每两个元素之间的涨幅,因为第一个元素之前没有元素,所以第一个值是NAN
print(ss)
#计算收益率最高和最低的信息
print(ss.idxmax()) #取最高收益率信息所对的索引(日期)
print(ss.idxmin()) #取低高收益率信息所对的索引(日期)
#波动率
print(ss.std()) #取标准差 波动率就是标准差
销售数据分析 -- resample重采样,rolling滑动窗口

环比:和上一个月比
同比:和去年这个月比
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#生成数据
sales = pd.Series([120,135,145,160,155,170,180,175,190,200,120,220],index=pd.date_range('2022-01-01',periods=12,freq='M'))#步长为M 按月生成
#季度平均效率
sales.resample('QS').count() #resample按时间频率重采样,传入值YS是按年采样,QS是按季采样. 后面跟统计值
#找到销量最高的月份
print('销量最高的月份',sales.max())
#计算月环比的增长率
print('月环比的增长率: ',sales.pct_change()) #百分率变化方法 计算每两个元素之间的涨幅 因为是相比上一个元素的涨幅,又是以月为单位 所以就求到月环比了
#计算连续增长超过两个月的月份
a = sales.pct_change() #计算增长率
b = a>0 #布尔索引,判断条件是增长率>0(为正的)
print(b[b.rolling(3).sum() == 3].keys()) #rolling:滑动窗口,概念:一个固定宽度的窗口在数据上滑动
#滑动窗口的数值(3)是窗口的大小,这里是3是匹配题目要求的连续两个月增长
# sum==3:窗口中的元素之和是否为3 这时满足连续增长两个月的月份的为索引的值为True
#[].keys()将这些布尔值对应的索引找到
Pandas DataFrame数据结构
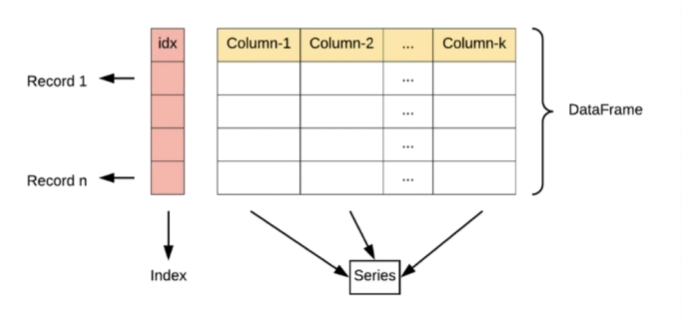
DataFrame是一个类似于表格的二维数据结构,有行和列.
DataFrame由多个Series组成,每一列都是一个series
DataFrame 每一行为一条记录,又名record每一行包含一个索引
DataFrame中 每一列可以是不同的数据类型
创建DataFrame数据
通过series创建dataframe
可以以{'列名',series}使用多个series构建一个dataframe
s1 = pd.Series([1,2,3,4,5])
s2 = pd.Series([6,7,8,9,10])
df = pd.DataFrame({'第一列':s1,'第二列':s2})
print(df)
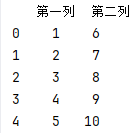
其实dataframe中每一列都是一个series
print(type(df['第一列'])) #查看名为df的Dataframe数据中的第一列类型

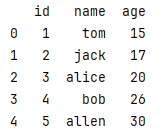
通过字典创建dataframe
= pd.DataFrame({"列名":[数据]})
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
}
)
print(df)
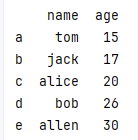
自定义索引
index=[]
df = pd.DataFrame(
{
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
},index=('a','b','c','d','e')
)
自定义列顺序
columns=[]
df = pd.DataFrame(
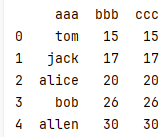
{
"aaa":['tom','jack','alice','bob','allen'],
"ccc":[15,17,20,26,30],
"bbb": [15, 17, 20, 26, 30],
},columns=["aaa","bbb","ccc"]
)
DataFrame属性
index
行索引
columns
列标签
values
df.values
DataFrame(按行)的值
格式:

dtypes
数据类型(元素类型)
df.dtypes
shape
形状
print(df.shape)
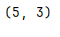 返回格式:(行,列)
返回格式:(行,列)
ndim
维度
df.ndim
size
返回整个Dataframe中的元素个数(元素个数)
df.size
返回格式:数值
loc[]
使用显式索引获取某行数据
df.loc[1] #传入参数[设置的索引]
使用显式索引获取某列数据
df = pd.DataFrame(
{
"ccc":[15,17,20,26,30],
"bbb": [15, 17, 20, 26, 30],
}
)
print(df.loc[:,'bbb']) # :,代表所有行
iloc[]
使用隐形式索引获取某行数据
df.iloc[系统的索引 从0开始分配]
使用隐式索引获取某列数据
df = pd.DataFrame(
{
"ccc":[15,17,20,26,30],
"bbb": [15, 17, 20, 26, 30],
}
)
print(df.iloc[:,1]) :,代表所有行
at[]
使用行列访问单个元素
.at[行,列]
df = pd.DataFrame(
{
"ccc":[15,17,20,26,30],
"bbb": [15, 17, 20, 26, 30],
}
)
print(df.at[2,1])
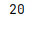
iat[]
使用行列表前访问单个元素
.iat[行,列]
df = pd.DataFrame(
{
"ccc":[15,17,20,26,30],
"bbb": [15, 17, 20, 26, 30],
}
)
print(df.iat[2,1])
T
.T
行列转置
原数据:
df = pd.DataFrame(
{
"ccc":[15,17,20,26,30],
"bbb": [15, 17, 20, 26, 30],
}
)
原数据格式:
转置后的数据格式:
print(df.T)

转置后行索引和列标签互换了
访问DataFrame数据
取某行值和具体某个值
loc/iloc/at/iat
从DataFrame中获取单列数据
方法1 :
df['列名']
方法2:
df.列名
获取到的单列数据的数据类型是series
从DataFrame中获取多列数据
df[['列名','列名']]
取到的数据是Dataframe
查看部分数据
取头部
.head()
取尾部
.tail()
布尔索引
.使用布尔索引筛选数据
使用单个条件进行筛选
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
"score":[100,70,60,50,80],
}
)
print([df[df.score>70])

使用多个条件进行筛选
print(df[(df.score>70) & (df.age<20)]) #and 同时满足两个条件
随机抽样
df.sample() #可传入参数:生成的条数
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
"score":[100,70,60,50,80],
}
)
print(df.sample(2))

DataFrame常用方法
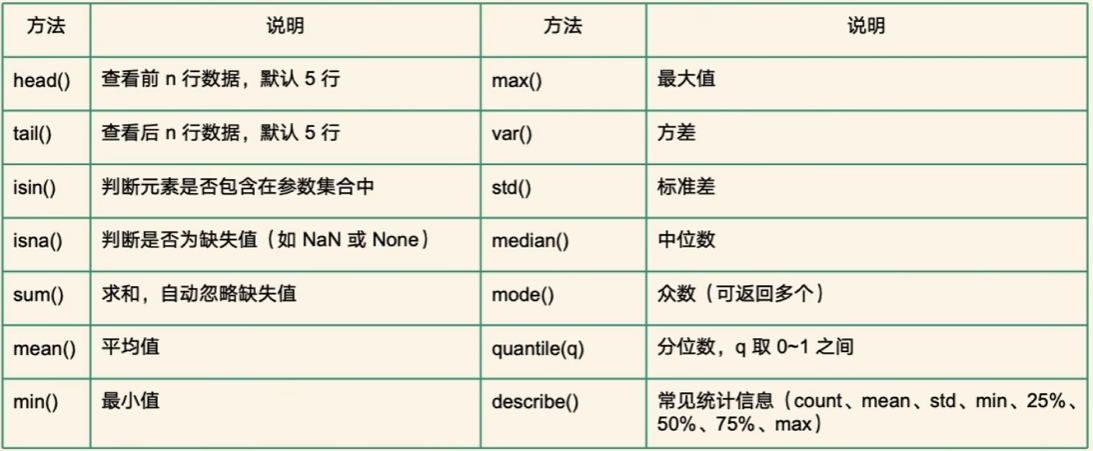
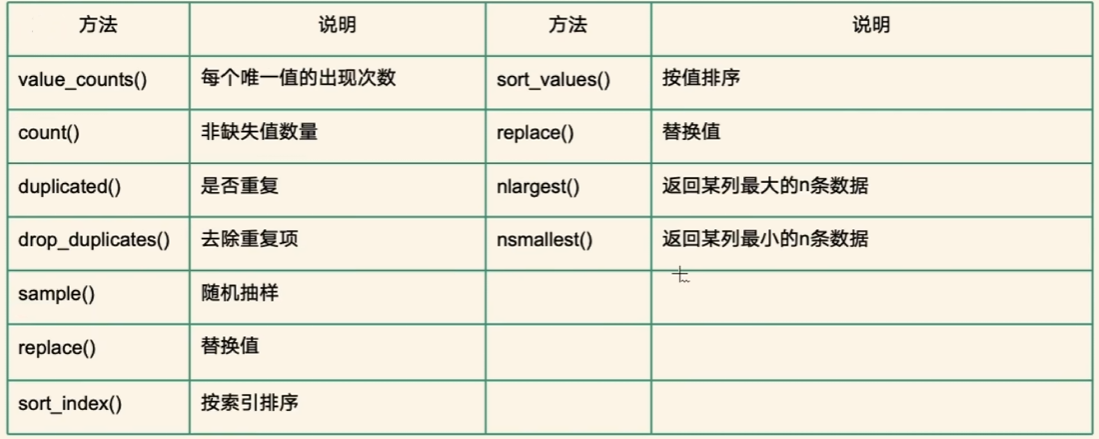
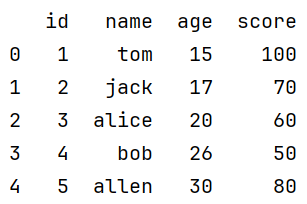
head()
.head(行数) 默认五行
查看前n行数据
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
"score":[100,70,60,50,80],
}
)
print(df.head())
tail()
.tail() 默认五行
查看后n行数据
isin()
.isin([元素]) 传入参数是一个集合[] , 要查找的参数都写在这个里面
判断元素是否包含在集合中
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
"score":[100,70,60,50,80],
}
)
print(df.isin(['jack'])) #查看元素是否包含在参数集合中
返回值为一个全是布尔值的集合

可以同时判断多个元素是否在集合中
print(df.isin(['jack',20]))

isna()
判断是否为缺失值
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
"score":[100,70,60,50,None],
}
)
print(df.isna())
 返回的值是一个布尔阵列,可以进行布尔索引
返回的值是一个布尔阵列,可以进行布尔索引
sum()
求和
dataframe中求和默认是按列求
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":['tom','jack','alice','bob','allen'],
"age":[15,17,20,26,30],
"score":[100,70,60,50,None],
}
)
print(df.sum())

求某一列的和:
print(df['age'].sum())
print(df.age.sum())
mean()
.mean()
平均值
求某一列平均值:
print(df['age'].mean())
print(df.age.mean())
min()
最小值
print(df['age'].min())
print(df.age.min())
max()
最大值
var
方差
数据离散的成都
.var()
std
标准差
数据离散的成都
.std
median
中位数
取某一列数值的中位数:
print(df['age'].median())
print(df.age.median())
mode()
众数,可返回多个
取某一列数值的众数:
print(df['age'].mode())
print(df.age.mode())
quantile(q)
.quantile(传入参数)
分位数,参数q在0~1之间
describe()
.describe()
常见统计信息
value_counts()
每个唯一值出现的次数,dataframe中的唯一值的单位是一整行
统计某个值的出现频率
df = pd.DataFrame(
{
"id":[1,1,3,4,5],
"name":['tom','tom','alice','bob','allen'],
"age":[15,15,20,26,30],
"score":[15,15,20,26,30],
}
)
print(df.value_counts())
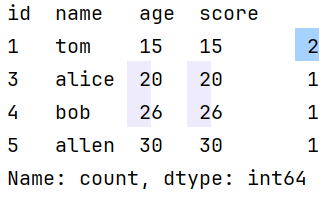
最后一列是统计出内容出现的次数
count()
统计非缺失值的数量
df.count()
df['列名'].count #统计一列中的元素数量
df['列1','列2'] #统计多列中的元素数量
duplicated
.duplicated()
检查是否重复(判断某一列之是否重复)
df = pd.DataFrame(
{
"id":[1,1,3,4,5],
"name":['tom','tom','alice','bob','allen'],
"age":[15,15,20,26,30],
"score":[15,15,20,26,30],
}
)
print(df.duplicated())

查看某一列是否有重复的:
duplicated(subset=['列名']
print(df.duplicated(subset=['score']))

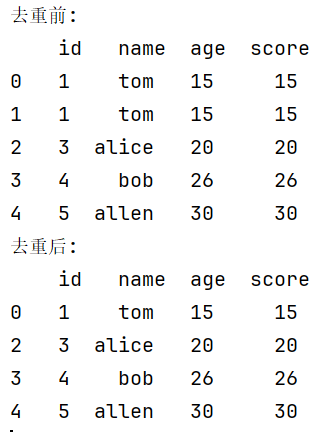
drop_duplicates()
去除重复项
df = pd.DataFrame(
{
"id":[1,1,3,4,5],
"name":['tom','tom','alice','bob','allen'],
"age":[15,15,20,26,30],
"score":[15,15,20,26,30],
}
)
print('去重前:\n',df)
print('去重后:\n',df.drop_duplicates())
sample
.sample(抽样数值)
随机抽样 - 随即从df中抽几列数据
replace
替换值
.replace(原数值,替换的数值)
df = pd.DataFrame(
{
"id":[1,1,3,4,5],
"name":['tom','tom','alice','bob','allen'],
"age":[15,15,20,26,30],
"score":[15,15,20,26,30],
}
)
print(df.replace(15,30)) #将df中所有为15的值替换为30
sort_index
按索引排序
.sort_index() 默认升序
参数:ascending=false 默认为True,false降序排序
sort_value
按值排序
.sort_value(by='列',ascending=t/F 升序和降序)
多列排序
.sort_value(by=['第一个参考列','第二个参考列'],ascending=['True','False'])
#对应第一列的排序方式, 对应第二列的排序方式(升序或降序)
nlargest
返回最大的n条数据
df.nlargest(要获取几条数据,columns=['依据','依据'])
nsmallest
返回最小的n条数据
df.nsmallest(要获取几条数据,columns=['依据','依据'])
累计相关
cusum()
参数axis =0时按列,=1时按行
累加
df = pd.DataFrame(
{
"id":[1,1,3,4,5],
"name":['tom','tom','alice','bob','allen'],
"age":[15,15,20,26,30],
"score":[15,15,20,26,30],
}
)
print(df.cumsum())
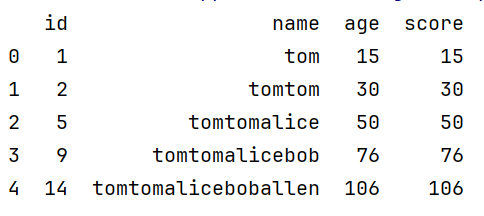
也可以对某一列进行累加
cummax()
参数axis =0时按列,=1时按行
累计最大值
和求一列的最大值效果一样
df = pd.DataFrame(
{
"id":[1,1,3,4,5],
"name":['tom','tom','alice','bob','allen'],
"age":[15,15,20,26,30],
"score":[15,15,20,26,30],
}
)
print(df.cummax())

cummin()
参数axis =0时按列,=1时按行
DATAFRAME案例
对DataFream数据的分析
学生成绩分析
销售数据分析
#已有学生的成绩数据如下
data = {
'姓名': ['张三','李四','王五','赵六','前七'],
'数学': [85,92,78,88,95],
'英语': [90,88,85,92,80],
'物理': [75,80,88,85,90]
}
#计算每位学生的总分和平均分
#找出数学成绩高于90分或英语成绩高于85分的学生
#按总分从高到低排序,并输出前三名学生
scores = pd.DataFrame(data) #将字典存入一个df
#计算每位学生的总分
scores['总分'] = scores[['数学','英语','物理']].sum()
#在socres中增加总分列 数值时从中取数学英语物理成绩并求和
#计算每个人的三科的平均分
scores['平均分'] = scores['总分'] / 3
scores['平均分方法2'] = scores['总分'].mean(axis=1) #axis = 1 横向计算
#找出数学成绩高于90分或英语成绩高于85分的学生
scores[(scores['数学']>90) | (scores['英语']>85)] #| 或关系
#总分从高到低排序 并输出前三名学生
scores.sort_values('总分').head(3) #按总分对成绩进行排序,再输出前三行即前三名
销售数据分析
#某公司销售数据如下
data = {
'产品名称': ['A','B','C','D'],
'单价': [100,150,200,120],
'销量':[50,30,20,40]
}
#计算每种产品的销售总额(销售额=单价x销量)
#找出销售额最高的产品
#次奥首恶从高到低排序
df = pd.DataFrame(data)
#计算总销售额
df['总销售额'] = df['单价']*df['销量']
#利用nlargest返回销售额列最大的1行数据
df.nlargest(1,columns=['总销售额'])
#按销售额从高到低排序
df.sort_values('总销售额',ascending=False) #排序,并按降序排序
电商用户行为分析
#某公司用户行为数据如下
data = {
'用户ID': [101,102,103,104,105],
'用户名': ['Alice','Bob','Charlie','David','Eve'],
'商品类别': ['电子产品','服饰','电子产品','家居','服饰'],
'商品单价': [12000,300,800,150,200],
'购买数量': [1,3,2,5,4]
}
#计算每位用户的总消费金额(消费金额 = 商品单价x购买数量)
#找出消费金额最高的用户,并输出其所有信息
#计算所有用户的平均消费金额(保留两位小鼠)
#统计电子产品的总购买数量
df = pd.DataFrame(data)
#计算每位用户的总消费金额
df['总消费金额'] = df['商品单价']*df['购买数量']
#找出消费金额最高的用户
df.nlargest(1,'总消费金额')
#计算所有用户的平均消费金额
df['总消费金额'].mean()
#计算电子产品总购买数量
df[df['商品类别'] == '电子产品']['购买数量'].sum()
#找出商品类别列值为电子产品的数据的购买数量数值并求和
Pandas数据分析
数据分析步骤
数据收集
数据的导入和导出
数据清洗
缺失值
错误数据
格式混乱
数据分析
统计(平均值/最大值/比例)
分组对比(对比差异)
数据可视化
折线图
柱状图
散点图
数据收集-导入导出
csv格式:通常 CSV 文件的第一行包含表格的列标签。随后的每一行代表表格的一行。逗号分隔行中的每个单元格,这就是名称的由来
数据的导入
1.将csv文件导入一个DataFrame
xxx = pd.read_csv('csv文件路径')
要注意绝对路径和相对路径的问题
2.将JSON文件导入一个DataFrame
xxx = pd.read_json('json文件路径')
数据的导出
1.将处理好的数据导出csv
xxx.to_csv('要导出的csv文件路径')
数据清洗-缺失值的处理
nan值: not a number 不是一个数值型的数值
缺失值的形式
Series中的缺失值
s = pd.Series([1,2,3,4,np.nan,None,pd.NA])
print(s)

Dataframe中的缺失值
s = pd.DataFrame([[1,pd.NA,2],[2,3,5],[None,4,6]])
print(s)

查看是否是缺失值
对于Series和DataFrame检查缺失值的方法是一致的
print(s.isna())
print(s.isnull())
查看缺失值的个数
(s.isna().sum())
处理缺失值
剔除缺失值
方法1:
.dropna()
如果是series 此方法会直接将缺失值移除
如果是DataFrame,在默认情况下此方法会直接将DataFrame中缺失值所在的整行移除(整条记录)如果不想要这种效果可以传入参数:
.dropna(how='all') DataFrame中,如果一行中所有的值都是缺失值,那么删除这一行
.dropna(thresh=n) DataFrame中,如果缺失值数量达到N个,那么删除这一行
其他用法:
.dropna(axis=1) #DataFrame剔除有缺失值的列的整列记录
.dropna(subset=['第1列']) #如果一行中的某列有缺失值,则删除这一行
s = pd.Series([1,2,pd.NA,8,None,10])
s2 = pd.DataFrame([[1,pd.NA,2],[2,3,5],[None,4,6]])
print(s.dropna())
print(s2.dropna())

填充缺失值
在空值位置填充固定值
xxx.fillna({'要填充的存在缺失值的列的名称':x}) #效果:将某一列的空值都填充为x
xxx.fillna(xxx[['要填充的存在缺失值的列的名称']].mean) #效果:将某一列的空值填充为这一列的平均值
xxx.ffill() #效果:根据缺失值附近的数据填充缺失值(复制前面的相邻数值填充)
xxx.bfill() #效果:根据缺失值附近的数据填充缺失值(复制后面的相邻数值填充)-
数据清洗-处理重复的数据
DataFrame中
查找重复行
.duplicated() #一整条记录都是一样的,标记为重复,返回True
直接去掉完全重复行
.drop_duplicates() 有多条完全重复的行,只保留一行(而且是第一行),后面的全部都删掉
根据指定的列去重
.drop_duplicates(subset=['name']) #将Name列数值重复的行都删掉. 只留一条(第一条)
保留最后一条
.drop_duplicates(subset=['name'],keep='last')
将Name列数值重复的行都删掉. 只留一条(第一条):keep='last'
数据清洗-数据类型的转换
type = object 通常为字符串数据,需要进行优化
数值转换类型
.astype(类型)
例如:
.astype(int16) .astype(int64) .astype(float64)
特殊数据类型-类别
方法1:将一个列的数据类型转换为分类:
.astype('category')
对于一列中只有几种数值的情况(例如性别列只有男女) 可以将其数据格式转换为类别(分类)
使用这个方法后这列的几种值会写到一个列表中,可以提高后期数据处理的效率
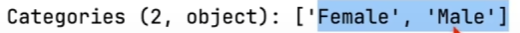
方法2:使用MAP将按数据映射成类别
.map({'男':True,'女':False}) #map 映射用
数据清洗-数据的变形和重塑
数据变形
行列转置
将df中的行列转换
.T
宽表转换长表
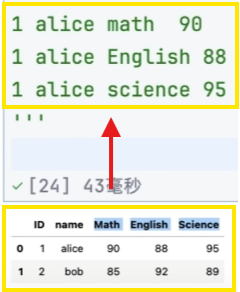 欲达到目的
欲达到目的
将宽表转换成原始数据形式的长表
pd.melt(df,id_vars=['ID','NAME'],var_name='科目',value_name='分数')
#(表,不变的字段的名称,转换后的列名)
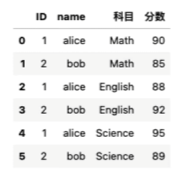 转换后的效果
转换后的效果
转换后的数据是按照varname排序的,我们可以再进行排序sort_Values('字段')
宽表转换长表
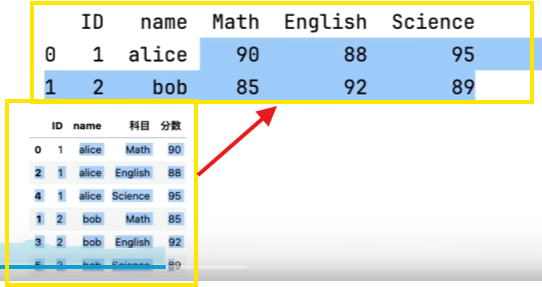 欲达目的
欲达目的
pd.pivot(df,index=['ID','name'],column='科目',values='分数')
( 表名, 不变字段的名称,列名的来源,数据的来源)
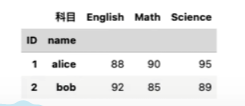 转换后的效果
转换后的效果
数据分列
用处:将一列符合信息转换为两列
例如将
"2023-10-05",分成三列year,month,day例如将
"name: Alice"分成两列key和value
语法
df名['列名'].str.split("分隔符",expand=True)效果:检测到分隔符是自动把数据隔开,参数expand:转成多列 这里的.str作为一个字符串选择器的作用
例如:
用分隔符姓和名
data = {
'name': ['aaa bbb','ccc ddd'],
}
df = pd.DataFrame(data)
df['name'].str.split(" ")#用空格作为分隔符
#可见 当数据中出现空格时,数据隔开成为两列数据
分割年月日 yy/mm/dd
df = pd.DataFrame({
"date": ["23/07/15", "24/01/09", "25/12/30"]
})
df[["yy", "nn", "dd"]] = df["date"].str.split("/", expand=True) #expand
print(df)
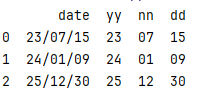 分割后的数据
分割后的数据
数据分箱
用处:
数据分箱(Data Binning)是一种常见的数据预处理方法,它将连续型数值变量划分成多个区间(bin),然后用这些区间的类别标签来代替原始的连续数值。
例如:划分工资为多个区间,划分年龄为多个年龄段
目的:
字符串--类别--统计
数值--分箱--统计
等宽分箱
把 数值范围 平均分成若干份,不考虑每个箱子里有多少个样本。
pd.cut(x,bins,labels,right)
x: 数值型数据(列), 格式例如:df['age']
bins: 连续区间(划分条件),
可以直接给数值bins=n 含义为将数据分为n段区间,起始值和结束值是数据的最小值和最大值.
也可以是给定的条件范围,格式为传入一个列表,里面是包含多个段的划分值: bins=[0, 18, 35, 60, 100]
tabels: 标签列表(指定每个区间的名字),
right: 区间是否右闭(数学上区间的左右闭开)
例:
df = pd.DataFrame({
"name": ["Alice", "Bob", "Cindy", "David", "Eric", "Fiona", "George", "Helen"],
"age": [12, 17, 23, 36, 45, 58, 67, 81]
})
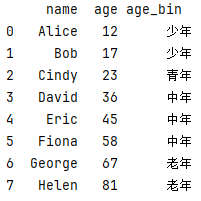
df["年龄范围"] = pd.cut(df["age"], bins=3, labels=["少年", "青年", "中年"], right=False)
print(df) #bins=3 根据已有的年龄数据 自动将年龄划分为三个区间
print(df['年龄范围'].value_counts())
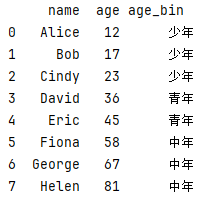
df = pd.DataFrame({
"name": ["Alice", "Bob", "Cindy", "David", "Eric", "Fiona", "George", "Helen"],
"age": [12, 17, 23, 36, 45, 58, 67, 81]
})
df["年龄范围"] = pd.cut(df["age"], bins=[0, 18, 35, 60, 100], labels=["少年", "青年", "中年", "老年"], right=False)
等频率分割
把 数据量(样本数量) 平均分成若干份,每个箱子大约有相同数量的样本。
qcut
import pandas as pd
df = pd.DataFrame({
"name": ["Alice", "Bob", "Cindy", "David", "Eric", "Fiona", "George", "Helen"],
"age": [12, 17, 23, 36, 45, 58, 67, 81]
})
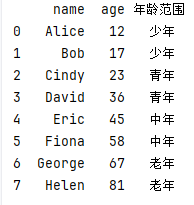
# 等频分箱
df["年龄范围"] = pd.qcut(df["age"], q=4, labels=["少年", "青年", "中年", "老年"])
print(df['年龄范围'].value_counts())
print(df)
数据清洗-其他的转换函数
df.rename()
给一个列重命名
rename(column={"age":"年龄"})
将原本为0的索引改为4
rename(index={0:4})
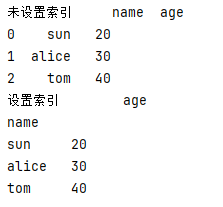
df.set_index()
设置索引名 - 将df中的一列设置为索引, 参数inplace:在当前的df上直接进行操作
df = pd.DataFrame({
'name': ['sun','alice','tom'],
'age': [20,30,40]
})
print('未设置索引',df)
df = df.set_index('name')
print('设置索引',df)
df.reset_index()
将自定义的索引重置回原先的0,1,2,3,...
.rest_index() #参数inplace:在当前的df上直接进行操作
df.index
直接设置索引
df.index=[1,2,3,4]
df.columns
修改列名
df.columns=["姓名","年龄","性别"]
数据清洗-时间数据的处理
数据分析时,把表格中的日期当作一种专门的时间格式数据进行处理
创建时间类型的数据
= pd.Timestamp
d = pd.Timestamp('2015-05-02 10:22:00')
创建好的时间数据类型:
print(type(d))
---
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
时间类型数据的属性
.year 年
.month 月
.day 日
.hour 小时
.minute 分钟
.second 秒
.quarter 季度
判断相关属性:
判断是否是年初/月底等 返回值:True/False
时间类型数据的常用方法
.day_name() 获取星期几
.to_period() 转换为周期 参数("D") -转换为天 / 参数("Q") -转换为季度 / 参数("Y") -转换为年/ 参数("W") -周
数据类型的转换
字符串转换为日期类型
=pd.to_datetime()
例如:
d = pd.to_datetime('2018-01-01')
转换后就可以用日期类型的属性和方法了
DataFrame转换日期类型
= pd.to_datetime(df名['日期所在列'])
df = pd.DataFrame(
{
'sales':[100,200,300],
'date':['20250601','20250602','20250603']
}
)
df['datatime'] = pd.to_datetime(df['date'])
.dt 日期选择器,可以快速把dataframe的数值型垒起转换为日期类型
df['datatime'] = df['datetime'].dt.day_name()
csv中读取的日期转换
在读取后操作:
将csv文件读取到dataframe中,csv中的日期在df里是字符串或者整数类型的,没法进行直接使用,所以需要转换
因此可以在读取到的df上再加一列,存放转换后的日期数据,这一列的数据类型是Date
df['datetime'] = pd.to_datetime(df['date'])
在读取时操作:
在读入csv时将指定的列转换为date数据类型 便后分析使用
= pd.readcsv('.csv路径',parse_dates=['date'])
日期数据作为索引
df.set_index('date') #将date列日期数据作为索引
用日期索引切片
df = pd.DataFrame(
{
'sales':[100,200,300],
'date':['20250601','20250602','20250603']
}
)
df = df.set_index('date') #将日期数据作为索引
print(df.loc['20250601':'20250602']) #使用日期索引切片
时间间隔类型(日期计算)
计算时间间隔
d1 = pd.Timestamp('2013-01-15')
d2 = pd.Timestamp('2023-02-23')
d3 = d2-d1
返回的数据
print(d3)
---
3691 days 00:00:00
返回的数据类型
print(type(d3))
---
<class 'pandas._libs.tslibs.timedeltas.Timedelta'>
计算出的d3并非时间类型,而是timedelta 时间间隔类型
时间间隔的实际使用
在数据表中建立时间间隔列,计算每列数据与索引为0(最早的时间的间隔)

用时间间隔作为索引(参数inplace为立即生效)

对时间间隔进行切片

时间序列类型
生成时间序列
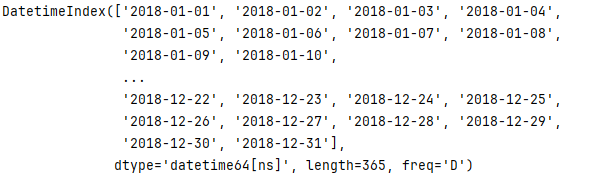
= pd.date_range('其实日期','结束日期') #参数freq - 步长,中间间隔的时间吗, 参数periods - 周期
时间序列的格式
重新采样
按时间维度(以时间为索引),对数据进行重新采样
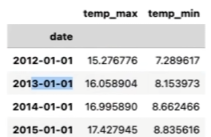
df.set_index('date',inplace=True) #设置时间数据为索引
例:按年为周期对"temp_max",和temp_min"列进行采样
df[ ["temp_max","temp_min"]].resample("YS").mean()
数据分析和统计-分组聚合
先分组,再做统计
df.groupby('分组的字段')['聚合的字段'].聚合的函数()
例:df.groupby('部门')['薪资'].max() #按部门分组找最高薪资
df.groupby(['','']).groups
.groups 查看分组
.get_group(分组) 查看具体的某个分组数据