目录索引
- 什么是特征工程?
- 加载数据集 (例:内置鸢尾花)
- 模型结构功能
- 数据集的划分 train_test_split
- 特征提取
- 遍历stopWords.txt的每一行并去掉空格形成列表
- 用每一列的平均值,填补 DataFrame 中的缺失值
- 给X中的给每个特征打分, 排序并选择前 K 个特征
- 将鸢尾花数据集从形状(150,4)降维到(150,2)
sklearn 特征呕逆过程到模型训练
什么是特征工程?
从原始素材数据中创建新的,对模型预测有帮助的特征(或称变量) 使机器学习算法能够更有效的工作 从而提升模型性能

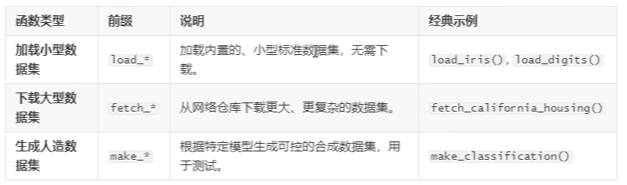
常见的数据集

SKLEARN自带的数据集
内置数据集,用于机器学习入门练习和快速验证算法模型

SKLEARN加载数据集方法
加载数据集 (例:内置鸢尾花)
加载内置数据集:
*from* sklearn.datasets *import* load_iris
*if* __name__ *==* '__main__':
*#加载鸳尾花数据集*
iris *=* load_iris()
数据集的数据:
iris 本质上是一个 字典(Bunch 对象),常见字段如下:
| 字段名 | 类型 | 含义 |
|---|---|---|
data |
ndarray (150, 4) | 特征数据(X) |
target |
ndarray (150,) | 标签(y) |
feature_names |
list | 每一列特征的名字 |
target_names |
ndarray | 每个类别的名称 |
DESCR |
str | 数据集说明文档 |
filename |
str | 数据集文件路径(有时存在) |
取其中的数据
print(iris['data'])
数据的信息(数据集的字段)

数据集中的主要字段 :data 和 target
1️⃣ data
iris.data
形状是:
(150, 4)
一共 150 条样本
每条样本有 4 个特征
这 4 个特征是什么?
iris.feature_names
结果是:
[
'sepal length (cm)', # 萼片长度
'sepal width (cm)', # 萼片宽度
'petal length (cm)', # 花瓣长度
'petal width (cm)' # 花瓣宽度
]
2️⃣ target
iris.target
内容类似:
[0 0 0 0 0 ... 1 1 1 ... 2 2 2]
每个数字代表一种花的类别:
iris.target_names
['setosa', 'versicolor', 'virginica']
这是监督学习中的“标准答案”,模型训练时要用它来对比预测结果
其他字段
DESCR
数据集说明
包含:数据来源/特征含义/样本数量/引用论文
print(iris.DESCR)
feature_names
画图时做坐标轴标签\转成 DataFrame 时作为列名\让代码更可读
iris.feature_names
常见写法:
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
target_names
把模型输出的 0 / 1 / 2 翻译成人类能看懂的类别
结果解释、可视化
概念 - 标准差
标准差: 描述数据离散程度的统计量
离散的概念: 不连续 可分离的数据和结构
模型结构功能
看“特征是什么”
特征名 / 列含义 :
get_feature_names_out()
记录“原始输入特征名”:
model.feature_names_in_
看“特征矩阵长什么样”
维度 / 稀疏性:
X.shape 返回: (样本数, 特征数)
模型实际接收到的特征数量:
model.n_features_in_
把稀疏矩阵变成“可读”的密集矩阵:
X.todense() X.toarray()
看“模型学到了什么”
每个特征的权重:
coef_
适用于:
LinearRegression
LogisticRegression
SGDClassifier
model.coef_
偏置项:
model.intercept_
树模型:
model.feature_importances_
看“类别 / 标签映射”
模型内部使用的类别顺序
clf.classes_
每一列的类别全集
enc.categories_
数据集的划分 train_test_split
我们需要把数据集进行划分,一部分用于训练构建模型,另一部分用于测试
train_test_split()是最常用的数据集划分方法之一,将数据随即划分为训练子集和测试子集
基本语法:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
train_size=None,
random_state=None,
shuffle=True,
stratify=None
)
参数:
x | y :x是特征数据集 通常是二维数组 y是目标变量 通常是一维数组
test_size: 测试集xy的比例或数量 (可填浮点数表示比例,整数表示绝对样本 默认NONE使用补集)
train_size: 训练集xy的比例或数量 (可填浮点数表示比例,整数表示绝对样本 默认NONE使用补集)
random_state: 随机种子 通过这个参数可以让每次划分的结果相同,控制复现 (整数或NONE)
shuffle: 是否在划分前随机打乱数据 (布尔值,默认TRUE)
stratify: 分层抽样,常用于分类问题中类别不平衡的情况 (数组-like对象,用于分层抽样, 默认NONE不进行分层)
例 - 对鸢尾花数据集的划分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
if __name__ == '__main__':
#加载鸳尾花数据集
iris = load_iris()
X_train,X_test,y_train,_y_test = train_test_split(iris.data, iris.target, test_size=0.2)
#训练集特征集 X_train
#训练集的目标值 y_train
#测试集特征集 X_test
#测试集的目标值 y_test
特征提取
把“类别型特征(字符串/离散标签)”转换成“模型能用的数字特征”
类别特征提取 - onehotencoder
将离散的无序的特征转换成一个二进制列
例如:
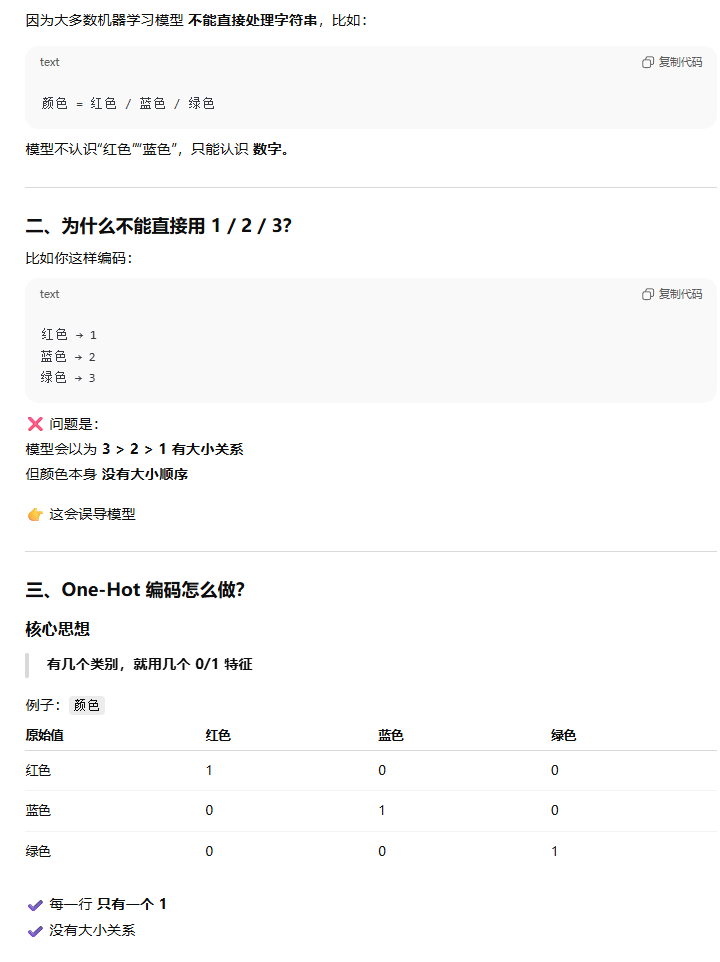
基本语法:
类别型特征”转换成“数值型特征
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder() #enc存放转换的编码规则
date = [['红色'], ['蓝色'], ['绿色']] #date: 传入列(可以是多列),也是要进行分类的数据(一列),这里为了方便直接写了一列 实际使用时这里可能是一个df['列']
enc.fit_transform(date).toarray() #编码,让编码器学习“编码规则”
这段代码对 date 这个数据中的“颜色这一列”进行了类别特征提取, 把“颜色这一列”直接转换成了一个 One-Hot 编码的矩阵. 注意编码结果只存在于 fit_transform / transform 的返回值中
.fit : 用于从训练数据生成学习模型参数
transfrom : 从fit方法生成的参数应用于模型以生成转换数据集
编码后的矩阵形状:
[[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]]
常用参数:
sparse_output
enc = OneHotEncoder(sparse_output=T/F) | 设置是否为稀疏矩阵 true: 稀疏矩阵(默认,省内存)False:普通 NumPy 矩阵(好理解、好看)
handle_unknown
handle_unknown 是给 OneHotEncoder 用的“转换规则 , 用处是:遇到未知类别时的操作
默认: handle_unknown='error' 一旦在 transform 阶段遇到 训练时没见过的类别,直接抛异常,程序终止
适用于要提取特征的数据绝对干净的情况
常用:handle_unknown='ignore' 遇到未知类别设置该特征对应的 One-Hot 全部置 0, 不报错,不区分不同未知值(都变成全 0)
categories
直接指定列中有哪些类别(唯一值)
默认auto, 正常情况就是编码器自动从传入的数据中找有哪些类别(自动进行分类并统计) 如果已经知道数据只分几种类别,可以用categorie
默认自动(auto) :
enc = OneHotEncoder(categories='auto')
手动指定(list):
enc = OneHotEncoder(categories=[['红色','蓝色','绿色']])
enc = OneHotEncoder(categories=[['红色','蓝色','绿色'], ['小','中','大']])
drop
在独热编码中,如果一个特征有 k 个类别,编码后会产生 k 个列。
有时会出现多重共线性. 如果模型不需要所有列,可以用 drop来减少
None: 默认,不丢弃任何类别 保留所有编码后的特征列
first: 丢弃每个特征的第一个类别 如果某个特征有k个类别,则会生成k-1列
enc = OneHotEncoder(drop='first')
sparse_output
用来控制 输出矩阵的存储类型
大数据/高维类别特征:sparse_output=True,节省内存。
小数据/需要直接用 NumPy 操作:sparse_output=False,操作更方便。
字典特征提取 - DictVectorizer
将特征名称和值映射为字典的列表抓换位数值矩阵, 用于处理混合类型的特征
使用场景:
处理类别特征:当特征是字典形式而不是 DataFrame 时非常方便。
特征工程:可以直接将键值对转换为矩阵用于机器学习模型。
文本数据的统计特征:比如词频统计可以直接用 DictVectorizer。
基本语法
实例
from sklearn.feature_extraction import DictVectorizer
data = [ #示例分类数据,列表中每个元素都是一个字典,代表一个样本
{'颜色': '红色', '大小': '大'},
{'颜色': '蓝色', '大小': '小'},
{'颜色': '绿色', '大小': '中'}
]
vec = DictVectorizer(sparse=False) # sparse=False 返回密集数组
X = vec.fit_transform(data)
print("特征名:", vec.get_feature_names_out())
print("特征矩阵:\n", X)
含义
自动从这些样本(字典)里自动找特征并分类为onehot
翻译后的数据格式:

输出:
特征名: ['颜色=红色' '颜色=蓝色' '颜色=绿色' '大小=大' '大小=小' '大小=中'] 特征矩阵: [[1. 0. 0. 1. 0. 0.] [0. 1. 0. 0. 1. 0.] [0. 0. 1. 0. 0. 1.]]
常用参数
dtype: 指定输出矩阵的数据类型。
DictVectorizer(dtype=int)
separator: 在生成特征名时,用于连接原字典的键和值,例如 颜色=红色
DictVectorizer(separator='__') # 特征名示例:颜色__红色
sparse: 控制输出矩阵是稀疏矩阵(True)还是密集矩阵(False)。
DictVectorizer(sparse=False)
sort: 是否对特征名按字母顺序排序,影响输出矩阵列的顺序
DictVectorizer(sort=False)
英文文本特征提取 - CountVectorizer
词袋模型 - CountVectorizer
核心功能:
将文本语料库转换为词频计数矩阵(也称词袋模型)
机器学习为什么不能直接用文本所以必须先做一步对文本特征提取(Feature Extraction)*
工作流程:
1.分词: 将每个文档(文本字符串)转换为单词(token)列表,
2.构建词表: 从所有文档中找出所有唯一的单词,并为其分配索引,这个词表被称为词典
3.编码与计数: 对每个文档,统计词表中每个单词出现的次数,形成一个向量
最终输出是一个矩阵,
矩阵的行代表每个文档, 列代表词表中每个单词, 值即是每个单词在对应文档中出现的次数
基本语法
*from* sklearn.feature_extraction.text *import* CountVectorizer
texts *=* [ #texts 数据源,进行特征工程的对象
"I love machine learning",
"I love Python",
"Python loves machine learning"
]
vectorizer *=* CountVectorizer( 参数 )
X *=* vectorizer.fit_transform(texts) #对文本特征学习并转换
print(vectorizer.get_feature_names_out()) #特征列表
特征矩阵:
print(X.toarray())
[[1 1 0 1 0] [0 1 0 0 1] [1 0 1 1 1]]
常用参数
CountVectorizer(
lowercase=True, #是否把文本全部转成小写
token_pattern=r'(?u)\b\w\w+\b', #定义“什么算一个词(token)”
stop_words=None, #去掉“无意义高频词” ,可以传入词表,也可是自带的词库. 内置:stop_words='english'
max_features=None, #最多保留多少个词(按词频排序)
min_df=1, #下线,出现次数太少的词丢掉
max_df=1.0, #上线,出现次数太多的词丢掉
ngram_range=(1, 1), #控制词的组合长度
analyzer='word', #按什么粒度”把文本拆成特征拆成什么级别
analyzer='word' → 看“词”
analyzer='char' → 看“字 / 字符”
analyzer='char_wb' → 看“词内部的字符片段”
binary=False #binary 当开启时,只关心“出现 / 未出现”,不关心出现次数 )
中文文本特征提取 - CountVectorizer
分词问题: 在英文文本特征提取时,使用空格作为分词. 如果要对中文进行提取 我们需要做中文分词
中文的分词
使用jieba库
pip install jieba
要做的:先用jieba库把中文数据转换成带空格的格式, 再使用词袋进行处理
*import* jieba #使用结巴库
*def* cut_word(input): #定义分词函数,对传入函数的值进行分词
*return* " ".join(list(jieba.cut(input)))#用空格对输入的值自动分词
print(cut_word('我是中国人')) #调用函数进行分词操作 传入参数这里是'我是中国人'
给词袋设置中文的stop_words
使用一个外部的 stopWords.txt
CountVectorizer(
stop_words=[line.strip() for line in open('stopWords.txt',encoding='utf-8').readlines()]
遍历stopWords.txt的每一行并去掉空格形成列表
)
加权 TF-IDF
TfidfVectorizer 用于信息检索和文本挖掘的加权计数 用以评估一个词语对于一个语料库中一份文档的重要程度
可以看作CountVectorizer的升级版 先使用CV的方法将文本转换为词频计数器 在应用TFIDF变换 对词频矩阵进行加权计算 将原始数据转换陈一个更能体现词语重要性的权重矩阵(就是获得一个矩阵,矩阵每个数值都是对应位文本的权重)
计算原理:
TfidfVectorizer 是 词袋模型 + TF-IDF 权重计算 的一体化工具
TF - 词频 一个词在当前文档中出现的频率 (文档:一条文本样本)
IDF - 一个词在整个语料库中普遍的重要性 (语料库:所有文档的集合)
TF-IDF = IDF TF*IDF
最终思想: 一个词的重要性会随着它在当前文档中出现的次数正比相加,但会随着它在整个语料库中出现的频率成反比下降. 这有效的过滤掉了常见的词语,保留了重要的词语
基本语法
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
"I like machine learning",
"I like python",
"machine learning is interesting"
]
vectorizer = TfidfVectorizer(参数) #实例化(Instantiation) / 初始化(Initialization)特征提取器
X = vectorizer.fit_transform(corpus)
print(X.toarray())
print(vectorizer.get_feature_names_out())
常用参数
1.input
可选:'content'(默认) / 'filename' / 'file' 表示你传入的是 文本内容本身
encoding
encoding='utf-8' 文本编码 中文文本经常显式写上,避免乱码
analyzer按什么粒度”把文本拆成特征拆成什么级别
'word':按词(默认)
'char':按字符
'char_wb':字符但只在词内
中文常用: analyzer='word' + tokenizer=jieba.lcut
-
tokenizer自定义分词函数 中文必用 TfidfVectorizer(tokenizer=jieba.lcut) -
ngram_range控制词的组合长度
(1,1):单词
(1,2):单词 + 二元词组
(2,2):只要二元词组
max_features只保留 TF-IDF 值最高的前 N 个词 防止维度爆炸
max_features=5000
min_df词至少在 多少个文档中出现
整数:min_df=2
比例:min_df=0.01(1% 文档)
max_df丢弃出现比例太高的词
max_df=0.8
-
stop_words停用词 和中英文文本特征提取规则一样. 中文有自己自己维护停用词表 -
use_idf是否使用 IDF 关掉就退化为 TF -
smooth_idf避免除零错误 -
sublinear_tf是否对词频 TF 做“次线性缩放” , 用于弱化高频词的影响
特征预处理
将原始数据转换为一组更具代表性, 更适合模型训练的特征的过程
处理缺失值 - SimpleImputer
SimpleImputer - sklearn 中用于缺失值填充的工具
工作方式:
用统计量或固定值,替换数据中的缺失值
基本语法
import numpy as np
from sklearn.impute import SimpleImputer
X = np.array([
[1, 2],
[3, np.nan],
[7, 6]
])
imputer = SimpleImputer(strategy='mean') 创建填充器(设定规则)
X_new = imputer.fit_transform(X) 拟合并转换数据
print(X_new)
常用参数
mean(均值) 数值型常用
SimpleImputer(strategy='mean')
median(中位数)对异常值更稳健
SimpleImputer(strategy='median')
most_frequent(众数) 类别特征常用
SimpleImputer(strategy='most_frequent')
constant(固定值)
SimpleImputer(strategy='constant', fill_value=0)
和pandasDF 一起用
用每一列的平均值,填补 DataFrame 中的缺失值
import pandas as pd
from sklearn.impute import SimpleImputer
df = pd.DataFrame({
'年龄': [18, 20, None, 22],
'收入': [3000, None, 5000, 6000]
})
imputer = SimpleImputer(strategy='mean') #创建缺失值填充器
df_new = pd.DataFrame( #创建新列, 内容是按“列均值”填补旧df 中的缺失值
imputer.fit_transform(df), #学习规则 + 应用规则
columns=df.columns #把原来 df 的列名,原样赋给“新的 DataFrame
)
print(df_new)
数据归一化 - MinMaxScaler
归一化的意义:
防止某些特征因为数值范围大而“主导”模型。
不同特征可能有不同的量纲和范围,归一化便使各特征在相同尺度上进行比较,防止某些特征数值较大而主导模型
翻译: 归一化就是把“单位不同、大小差很多的数据”,统一换成同一个尺度,让模型别被“大数字”骗了。
例如: 年龄用“岁”,收入用“元” . 归一化就像 把它们都换算成同一种“分数”来比较,而不是直接比谁数字大。
用处: 加快收敛速度 , 提高数值稳定性, 避免梯度震荡
归一化后单位“消失”了,原数据有单位:cm、kg、元…… 归一化后:没有物理单位,只剩“相对大小”
需要对数据归一化的算法:
| 算法 | 是否需要归一化 |
|---|---|
| KNN | ✅ 必须 |
| KMeans | ✅ 必须 |
| SVM | ✅ 强烈建议 |
| 线性回归(梯度下降) | ✅ |
| 逻辑回归 | ✅ |
| PCA | ✅ |
| 神经网络 | ✅ |
MinMaxScaler
sklearn中最经典的归一化, 缩放到指定区间(默认 0~1)
语法代码:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler() #创建一个归一化器对象
X_new = scaler.fit_transform(X) #学习规则 并按规则缩放数据.(实现对数据的自动归一化)
#代码实现操作: 对X中的数据进行归一化处理并保存到X_new
参数:
MinMaxScaler(
feature_range=(0, 1), #指定归一化后的数值范围 默认0,1
copy=True, # 是否复制一份新数据 默认TRUE, 为False时数据直接掩盖X
clip=False #是否对“超出训练范围的数据”进行裁剪
)
数据标准化 - StandardScaler
标准化的意义
拉平特征分布,让模型“公平理解每个特征的波动和偏离”
模型在训练时不会被某个波动大的特征“拉偏”,每个特征都被公平对待。
标准化就是把所有特征都“搬到同一个起跑线”,让模型看每个特征的“超出平均多少”,而不是看绝对数值大小。
需要对数据标准化的算法
| 算法类别 | 示例 | 原因 |
|---|---|---|
| 线性模型 | 线性回归、逻辑回归(Logistic Regression) | 梯度下降优化时,特征尺度差异会影响收敛速度 |
| 支持向量机 | SVM | 核函数(如 RBF)计算距离,尺度不同会影响分类边界 |
| K 近邻 | KNN | 距离度量(欧氏距离)依赖特征尺度 |
| 聚类 | K-means | 距离度量敏感,特征大值会主导聚类结果 |
| 主成分分析 | PCA | 要求特征方差一致,否则方差大的特征会主导主成分 |
| 神经网络 | 神经网络(尤其是使用 sigmoid/tanh) | 梯度下降收敛更快,避免梯度消失或爆炸 |
语法代码:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() #创建一个标准化器对象
X_new = scaler.fit_transform(X) #学习并转换数据,得到标准化后的新数据
参数:
| 参数 | 类型 | 默认值 | 作用 |
|---|---|---|---|
copy |
bool | True | 是否复制数据。True 会返回新数组,不修改原数据;False 则可能会覆盖原数据 |
with_mean |
bool | True | 是否 去均值(减去每列平均值)。如果你的数据是稀疏矩阵,必须设为 False |
with_std |
bool | True | 是否 缩放标准差(除以标准差)。如果 False,则只做去均值,不缩放方差 |
特征降维 压缩数据
什么是降维和压缩
特征选择: 从原始特征中挑出对模型最有用的部分,去掉不重要或冗余的特征。简单来说,就是 帮模型“减负”,只留下关键特征”。
| 方法类别 | 解释 | 举例 |
|---|---|---|
| 过滤法(Filter) | 根据特征和目标变量的统计关系选特征,独立于模型 | 相关系数、卡方检验、方差选择 |
| 包裹法(Wrapper) | 使用模型训练效果来评估特征组合,挑最优组合 | 递归特征消除(RFE)、前向选择、后向选择 |
| 嵌入法(Embedded) | 特征选择在模型训练过程中完成 | Lasso回归(带L1正则)、决策树特征重要性 |
数据压缩: 用更少的存储空间或特征维度来表示原始数据,同时尽量保留数据中重要的信息。简单说,就是 “用更小、更精简的形式表达数据”。
| 类型 | 说明 | 举例 |
|---|---|---|
| 无损压缩 | 压缩后可以完全恢复原始数据 | ZIP 压缩、PNG 图像 |
| 有损压缩 | 压缩后数据无法完全恢复,但保留主要信息 | JPEG 图像、音频 MP3、PCA 特征压缩 |
| 降维压缩 | 减少特征维度,保留数据主要信息 | PCA(主成分分析)、LDA(线性判别分析)、Autoencoder(自编码器) |
特征选择
从原始数据中挑出对模型最有用的特征
移除低方差特征 - VarianceThreshold
低方差特征: 在所有样本中,这个特征的值变化很小,或者完全不变 .
常见示例:
特征 样本值 方差 说明 性别 [男, 男, 男] 0 恒定,低方差 国籍 [中国, 中国, 中国] 0 恒定,低方差 年龄 [20, 25, 30] 高 有变化,高方差 → 有信息
意义
找出那些 在样本中几乎不变化 的特征, 并将它们 从数据中移除.
这些信息提供的信息很少,对模型预测帮助不大. (例如性别列里几乎全是“男”,这一列对分类模型几乎没贡献。)
操作
自动删除方差低于指定阈值的特征 属于:无监督特征选择(不依赖目标变量)
语法代码:
from sklearn.feature_selection import VarianceThreshold
import numpy as np
X = np.array([
[1, 0, 3],
[1, 1, 3],
[1, 0, 3]
])
selector *=* VarianceThreshold(threshold*=*0.0) #删除方差为 0 的特征(完全不变化的特征)
X_new *=* selector.fit_transform(X)
print(X_new)
常用参数
threshold -- 方差阈值,低于该值的特征会被移除 -- 默认值:0.0
单变量特征选择 - SelectKBest
意义
单独评估每个特征的重要性,然后挑出对预测最有用的特征。 实现只保留重要特征,从而从而减少噪声和冗余
单变量特征选择就好比在挑考试题目 一道一道题看它是否有区分能力(高分和低分的学生差异明显的题)
能区分学生的题 → 保留 无差别的题 → 删掉
操作
打分 + 挑最强特征:先给每个特征评分,再选出前 k 个最重要的特征供模型使用。
从原始特征中“挑出最重要的 K 个特征”,返回一个新的特征矩阵**。
语法代码
from sklearn.feature_selection import SelectKBest, f_classif # f_classif 用于分类问题
import numpy as np
X = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[1, 0, 1]
])
y = np.array([0, 1, 1, 0]) # 分类标签
selector = SelectKBest(score_func=f_classif, k=2) # 选择 2 个最重要的特征
给X中的给每个特征打分, 排序并选择前 K 个特征
X_new = selector.fit_transform(X, y)
print(X_new)
print("得分:", selector.scores_) # 每个特征的评分
print("被选择的特征:", selector.get_support()) # 布尔数组,True 表示被选中
输出值:
[[2 3] #可以看到模型从三列中自动选择了更重要的两列(k=2)特征 [5 6] [8 9] [0 1]] 得分: [9. 9.30769231 9.30769231] 被选择的特征: [False True True] #选了了二三列
常用参数
f_classif:方差分析 F 检验(分类任务) #检查每个特征与目标变量 y 之间的线性关系是否显著
chi2:卡方检验(分类任务,要求特征非负) #衡量每个特征与目标变量的独立性
mutual_info_classif:互信息(分类任务) #衡量特征与目标之间的信息共享程度(不要求线性关系)
mutual_info_regression:互信息(回归任务) #衡量特征与连续目标之间的信息共享程度。
| score_func | 任务类型 | 特征要求 | 主要特点 |
|---|---|---|---|
| f_classif | 分类 | 数值型 | 检测线性关系,F 值越大越重要 |
| chi2 | 分类 | 非负特征 | 检测相关性,卡方值越大越重要 |
| mutual_info_classif | 分类 | 数值或类别均可 | 捕捉非线性关系,互信息越大越重要 |
| mutual_info_regression | 回归 | 数值型 | 捕捉非线性关系,互信息越大越重要 |
特征提取
把原来的特征“重新组合/压缩”,生成全新的特征(造新列). 实现用更少的维度,保留尽量多的“关键信息”
PCA - 主成分分析: 找数据中 变化最大的方向 , 把数据投影到这些方向上, 丢掉变化小(信息少)的方向
从“多个角度看物体”, 选 最能看清轮廓的几个角度 保留方差(不看标签)
LDA - 线性判别分析: 找 最能区分不同类别 的特征方向, 压缩维度的同时增强分类能力 拉开类别(看标签)
主成分分析 - PCA
在主成分分析之前 需要对数据先进性标准化处理
语法代码(实例):
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import numpy as np
X = np.array([ #数据集
[2.5, 2.4],
[0.5, 0.7],
[2.2, 2.9],
[1.9, 2.2],
[3.1, 3.0],
[2.3, 2.7],
[2, 1.6],
[1, 1.1],
[1.5, 1.6],
[1.1, 0.9]
])
scaler = StandardScaler()
X_std = scaler.fit_transform(X) #数据标准化处理
pca = PCA(n_components=1)# 参数
X_pca = pca.fit_transform(X_std) #对标准化的数据进行主成分分析
常见参数
PCA(
n_components=None, # 指定降到多少维 如,PCA(n_components=2) / 指定保留多少信息(方差比例)如,PCA(n_components=0.95) - 保留 95% 信息
whiten=False, #让输出特征 方差为 1, 常用于:SVM、KNN 等对尺度敏感模型, 一般情况:不需要开
svd_solver='auto', #auto'默认 , 'randomized'(大数据时更快)
random_state=None #种子数 ,控制随机可复现
)
线性判别分析 - LinearDiscriminantAnalysis
LDA 会让 不同类别的中心(均值)在投影后尽量远离。实现 最大化类间散度,从而更容易区分类别
LDA 会让 同一类别的数据在投影后尽量集中 实现 同一类样本 → 聚在一起 做到最小化类内散度
做降维
监督式降维, 找最能区分类别的低维表示
代码:
将鸢尾花数据集从形状(150,4)降维到(150,2)
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X, y = load_iris(return_X_y=True) #加载数据,return_X_y=True : 只加载x和y
lda = LinearDiscriminantAnalysis(n_components=2) #定义 LDA(指定降到 2 维)
X_lda = lda.fit_transform(X, y) #拟合并降维
print(X_lda.shape) #输出降维后的形状 - (150, 2)
参数:
LinearDiscriminantAnalysis(
`n_components=None, #降维维度数,只在做降维时有意义, n_components ≤ min(特征数, 类别数 - 1)
solver='svd', #求解方式 可选值: 'svd' - 不计算协方差矩阵,稳定 (一般情况) / 'lsqr' - 支持 shrinkage,适合小样本高维/ 'eigen' - 特征值分解,也支持 shrinkage
shrinkage=None, #协方差收缩 - 防止过拟合 让协方差矩阵更稳定 . None`,不使用收缩 / 'auto'
自动选择收缩系数 / 0~1`` 手动指定收缩强度
协方差收缩: 描述“特征之间如何一起变化”的表
priors=None, #你认为每个类别出现的概率 默认从训练数据中自动计算,
对于类别不平衡场景:
lda = LinearDiscriminantAnalysis(
priors=[0.7, 0.3])
tol=1e-4,#收敛阈值
store_covariance=False, #是否保存每个类别的协方差矩阵
covariance_estimator=None #自定义协方差估计器
)
做分类
在这个判别子空间里做决策,直接预测类别
代码:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)
y_pred = lda.predict(X_test)
accuracy = lda.score(X_test, y_test)
print("准确率:", accuracy)
lda.fit(X_train, y_train):训练模型lda.predict(X_test):用训练好的模型进行分类预测lda.score(X_test, y_test):返回分类准确率
参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
solver |
求解方法,分类时常用的三种 | 'svd' |
'svd' |
无正则化,适合小样本高维数据,自动进行降维 | - |
'lsqr' |
带 shrinkage(收缩)正则化的最小二乘解,适合特征数大 | - |
'eigen' |
基于特征值分解,适合需要正则化 | - |
shrinkage |
收缩系数(只在 solver='lsqr' 或 'eigen' 时可用) |
None |
priors |
每类的先验概率,默认按训练集比例 | None |
store_covariance |
是否存储类内协方差矩阵 | False |
tol |
收敛容差,影响数值稳定性 | 1e-4 |
分类算法
K临近 - KNN
KNN 的本质是基于样本在特征空间的相似性来进行预测。既可以用于分类,也可以用于回归。它的核心思想是:“物以类聚,人以群分”——即一个样本的类别(或数值)主要由它周围最邻近的样本决定。
概念:
K:指的是算法在判断一个样本所属类别时,参考的最近邻居的数量。
邻居(Neighbor):与当前样本在特征空间中距离最近的样本。
距离度量:常用欧氏距离(Euclidean)、曼哈顿距离(Manhattan)、闵可夫斯基距离(Minkowski)等,用来判断样本之间的相似度。
代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
#加载数据
iris = load_iris()
X = iris.data # 特征
y = iris.target # 标签
#划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
#对数据标准化,减小数据特征量纲差别
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
#创建KNN模型
knn = KNeighborsClassifier(n_neighbors=3) # k值设置为3
#训练模型
knn.fit(X_train, y_train)
#---预测---
y_pred = knn.predict(X_test)
#---评估---
#准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
#混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", cm)
参数
knn = KNeighborsClassifier(
n_neighbors=3, #指定用于投票的邻居数量(k 值)如:n_neighbors=3 表示使用最靠近的 3 个邻居进行分类
weights='distance', #权重分配方式 , 'uniform': 所有邻居权重相同, 'distance':距离越近权重越大
algorithm='auto',#用于计算最近邻的方法
参数:
'auto':自动选择最合适算法
'ball_tree' / 'kd_tree':树结构算法,适合大数据
'brute':暴力搜索,计算所有点距离
p=2, #距离度量参数,默认2 | p=1 → 曼哈顿距离,p=2 → 欧氏距离,n_jobs=-1
)
评估指标
使用模型进行预测: y_pred *=* knn.predict(X_test)
分类任务
准确率 Accuracy:
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)
精确率 Precision:
precision = precision_score(y_test, y_pred, average='macro') # 'macro'针对多分类
print("Precision:", precision)
召回率 Recall:
recall = recall_score(y_test, y_pred, average='macro')
print("Recall:", recall)
F1-score:
f1 = f1_score(y_test, y_pred, average='macro')
print("F1-score:", f1)
混淆矩阵 Confusion Matrix:
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", cm)
ROC-AUC(针对二分类):
y_prob = knn.predict_proba(X_test)[:, 1] # 获取正类概率
auc = roc_auc_score(y_test, y_prob)
print("AUC:", auc)
回归任务
均方误差 MSE
mse = mean_squared_error(y_test, y_pred)
print("MSE:", mse)
均方根误差 RMSE:
rmse = np.sqrt(mse)
print("RMSE:", rmse)
平均绝对误差 MAE:
mae = mean_absolute_error(y_test, y_pred)
print("MAE:", mae)
决定系数 R²:
r2 = r2_score(y_test, y_pred)
print("R²:", r2)
逻辑回归 - Logistic Regression
预测类型:分类
输出: 输出是概率值 ,表示属于某个类别的可能性
例子:
- 病人是否患病:根据年龄、血压、症状预测“患病/不患病”。
- 邮件是否垃圾邮件:根据词频、发件人信息预测“垃圾/非垃圾”。
- 客户是否流失:根据购买记录预测“流失/未流失”。
代码
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import pandas as pd
import numpy as np
#-------------样本数据------------
n_samples = 100 # 样本数量
df = pd.DataFrame({
'年龄': np.random.randint(18, 60, size=n_samples), # 数值特征1
'收入': np.random.randint(3000, 10000, size=n_samples), # 数值特征2
'消费评分': np.random.randint(1, 10, size=n_samples), # 数值特征3
'是否购买': np.random.choice([0, 1], size=n_samples) # 标签(0=未购买,1=购买)
})
#--------------划分数据的特征和标签-----------
X = df.drop('是否购买', axis=1)
y = df['是否购买']
#--------------划分训练集和测试集---------------
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#--------------创建逻辑回归模型并训练-----------------
model = LogisticRegression(solver='liblinear') # 参数solver可选 'liblinear', 'lbfgs', 'saga' 等
model.fit(X_train, y_train)
#-----------使用模型预测-------------
y_pred = model.predict(X_test)
#------------模型评估-----------------
print("Accuracy:", accuracy_score(y_test, y_pred))
#混淆矩阵
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
#分类报告(精确率、召回率、F1-score)
print("Classification Report:\n", classification_report(y_test, y_pred))
#-------------预测概率--------------------
y_prob = model.predict_proba(X_test) #得到预测为每个类别的概率
print(y_prob[:5]) # 显示前5个样本的概率
参数
1. 核心参数
| 参数 | 作用 | 默认值 |
|---|---|---|
penalty |
惩罚项类型,用于正则化 | 'l2' |
dual |
是否用对偶形式求解(只对 l2 且 solver='liblinear' 有效) |
False |
C |
正则化强度的倒数,值越小正则化越强 | 1.0 |
fit_intercept |
是否拟合截距项 | True |
intercept_scaling |
当使用 solver='liblinear' 且 fit_intercept=True 时,拦截的缩放 |
1 |
class_weight |
类别权重,可调整样本不平衡问题 | None |
random_state |
随机种子 | None |
max_iter |
最大迭代次数 | 100 |
2. 优化相关参数
| 参数 | 作用 | 默认值 |
|---|---|---|
solver |
优化算法选择 | 'lbfgs' |
tol |
收敛阈值 | 1e-4 |
multi_class |
多分类策略,可选 'auto', 'ovr'(一对多), 'multinomial'(softmax) |
'auto' |
verbose |
打印训练信息 | 0 |
warm_start |
是否使用上一次拟合结果作为初始化 | False |
n_jobs |
并行运行数(只对 solver='saga' 有效) |
None |
l1_ratio |
ElasticNet 中 L1 与 L2 的比例(仅 penalty='elasticnet' 且 solver='saga' 有效) |
None |
评估指标
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
准确率(Accuracy):
accuracy = accuracy_score(y_test, y_pred)
精确率(Precision):
precision = precision_score(y_test, y_pred)
召回率(Recall / Sensitivity):
recall = recall_score(y_test, y_pred)
F1-score :
f1 = f1_score(y_test, y_pred)
ROC-AUC :
roc_auc = roc_auc_score(y_test, y_prob)
混淆矩阵:
cm = confusion_matrix(y_test, y_pred)
回归分析算法
线性回归:
线性回归用于预测连续型变量的数值。 - 一个线性函数(直线或高维空间的平面)去拟合输入特征和目标值之间的关系
使用场景 - 例如:
- 房价预测:根据面积、房间数量、地段等预测房屋价格。
- 工资预测:根据工作年限、学历、行业等预测工资水平。
- 销售量预测:根据广告投入、季节因素等预测产品销量
代码
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression #线性回归库
from sklearn.metrics import mean_squared_error, r2_score #评估指标库
#示例数据:房屋面积(平方米) vs 房价(万元)
data = {
'面积': [50, 60, 70, 80, 90, 100],
'房价': [150, 180, 210, 240, 270, 300]
}
df = pd.DataFrame(data)
#特征X和目标y
X = df[['面积']] # 注意X要是二维数组
y = df['房价']
#拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
#创建模型
model = LinearRegression()
#训练模型
model.fit(X_train, y_train)
#训练中模型的参数
print("回归系数(斜率):", model.coef_)
print("截距:", model.intercept_)
#----------------使用模型预测-----------------
y_pred = model.predict(X_test) #预测
print("预测结果:", y_pred)
print("真实结果:", y_test.values)
#----------- 模型评估 ------------
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("均方误差:", mse)
print("R²分数:", r2)
参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
fit_intercept |
bool | True |
是否计算截距(intercept)。如果设为 False,模型不会计算截距,假定数据已经中心化。 |
copy_X |
bool | True |
是否复制 X 数组。True 表示在拟合过程中不修改原始 X 数据;False 表示可能会直接修改原数据。 |
n_jobs |
int 或 None |
None |
用于并行计算的线程数。None 表示使用单线程;-1 表示使用所有CPU核心。 |
positive |
bool | False |
是否强制约束系数为正值(非负线性回归)。设为 True 时所有系数都会被限制为 ≥0。 |
评估指标
均方误差 (Mean Squared Error, MSE)
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_pred)
均方根误差 (Root Mean Squared Error, RMSE)
import numpy as np
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
平均绝对误差 (Mean Absolute Error, MAE)
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_true, y_pred)
决定系数 (R² Score)
from sklearn.metrics import r2_score
r2 = r2_score(y_true, y_pred)